El rol del Kernel
El kernel del sistema operativo es como un controlador de tráfico aéreo en un aeropuerto. El kernel determina que programa obtiene que pedazos de memoria, arranca y mata a los programas, y se encarga de mostrar texto en un monitor. Cuando una aplicación necesita escribir en disco, debe pedir al sistema operativo que lo haga. Si dos aplicaciones piden el mismo recurso, el kernel decide cuál de las dos lo recibe y en algunos casos, mata a una de las aplicaciones para salvar el resto del sistema.
El kernel también se encarga de cambiar entre aplicaciones. Un equipo tendrá un pequeño número de procesadores CPU y una cantidad finita de memoria. El kernel se encarga de descargar una tarea y cargar una nueva si hay más tareas que CPUs. Cuando la tarea actual se ha ejecutado una cantidad suficiente de tiempo, la CPU detiene la tarea para que otra pueda ejecutarse. Esto se llama multitarea preferente. Multitarea significa que la computadora realiza varias tareas a la vez, preferente significa que el kernel decide cuándo cambia el enfoque entre las tareas.
El software de Linux cae generalmente en una de tres categorías:
- Software de servidor – software que no tiene ninguna interacción directa con el monitor y el teclado de la máquina en la que se ejecuta. Su propósito es servir de información a otras computadoras llamados clientes. A veces el software de servidor puede no interactuar con otros equipos, sin embrago, va a estar ahí sentado y «procesando» datos.
- Software de escritorio – un navegador web, editor de texto, reproductor de música u otro software con el que tú interactúas. En muchos casos, como un navegador web, el software consultará a un servidor en el otro extremo e interpretará los datos para ti. Aquí, el software de escritorio es el cliente.
- Herramientas – una categoría adicional de software que existe para que sea más fácil gestionar el sistema. Puedes tener una herramienta que te ayude a configurar la pantalla o algo que proporcione un shell de Linux o incluso herramientas más sofisticadas que convierten el código fuente en algo que la computadora pueda ejecutar.
Adicionalmente, vamos a ver las aplicaciones móviles, principalmente para el beneficio del examen LPI. Una aplicación móvil es muy parecida a una aplicación de escritorio pero se ejecuta en un teléfono o una tableta en lugar de una maquina de escritorio.
Uno de los primeros usos de Linux era para servidores web. Un servidor web aloja contenido para páginas web a las que ve el explorador web mediante el Protocolo de transferencia de hipertexto (HTTP – Hypertext Transfer Protocol) o su forma cifrada HTTPS.
El correo electrónico (e-mail) siempre ha sido un uso popular para servidores Linux. Cuando se habla de servidores de correo electrónico siempre es útil considerar las 3 funciones diferentes para recibir correo electrónico entre personas:
- Agente de transferencia de correo (MTA- Mail Transfer Agent) – decide qué servidor debe recibir el correo electrónico y utiliza el Protocolo simple de transferencia de correo (SMTP- Simple Mail Transfer Protocol) para mover el correo electrónico hacia tal servidor. No es inusual que un correo electrónico tome varios «saltos» para llegar a su destino final, ya que una organización puede tener varios MTAs.
- Agente de entrega de correo (MDA- Mail Delivery Agent, también llamado el Agente de entrega local) se encarga de almacenar el correo electrónico en el buzón del usuario. Generalmente se invoca desde el MTA al final de la cadena.
- Servidor POP/IMAP – (Post Office Protocol e Internet Message Access Protocol) son dos protocolos de comunicación que permiten a un cliente de correo funcionando en tu computadora actuar con un servidor remoto para recoger el correo electrónico.
Dovecot es un servidor POP/IMAP popular gracias a su facilidad de uso y bajo mantenimiento. Cyrus IMAP es otra opción.
Para compartir archivos, Samba es el ganador sin duda. Samba permite que una máquina Linux se parezca a una máquina Windows para que pueda compartir archivos y participar en un dominio de Windows. Samba implementa los componentes del servidor, tales como archivos disponibles para compartir y ciertas funciones de servidor de Windows, así como el cliente para que una máquina de Linux puede consumir un recurso compartido de archivos de Windows.
Si tiene máquinas Apple en la red, el proyecto Netatalk permite que tu máquina Linux se comporte como un servidor de archivos de Apple.
El protocolo para compartir el archivo nativo para UNIX se llama Sistema de Archivos de Red (NFS-Network File System). NFS es generalmente parte del kernel lo que significa que un sistema de archivos remoto puede montarse como un disco regular, haciendo el acceso al archivo transparente para otras aplicaciones.
El DNS se centra en gran parte en nombres de equipos y direcciones IP y no es fácilmente accesible. Han surgido otros directorios para almacenar información distinta tales como cuentas de usuario y roles de seguridad. El Protocolo ligero de acceso a directorios (LDAP- Lightweight Directory Access Protocol) es el directorio más común que alimenta también el Active Directory de Microsoft. En el LDAP, un objeto se almacena en una forma de árbol (ramificada), y la posición de tal objeto en el árbol se puede utilizar para obtener información sobre el objeto, además de lo que se almacena en el objeto en sí. Por ejemplo, un administrador de Linux puede almacenarse en una rama del árbol llamado «Departamento TI», que está debajo de una rama llamada «Operaciones». Así uno puede encontrar personal técnico buscando bajo la rama del Departamento TI. OpenLDAP es aquí el jugador dominante.
Una última pieza de la infraestructura de red se denomina el Protocolo de configuración dinámica de Host (DHCP- Dynamic Host Configuration Protocol). Cuando un equipo arranca, necesita una dirección IP para la red local por lo que puede identificarse de manera unica. El trabajo de DHCP sirve para identificar las solicitudes y asignar una dirección disponible del grupo DHCP. La entidad Internet Software Consortium también mantiene el servidor ISC DHCP que es el jugador más común.
Una base de datos almacena la información y también permite una recuperación y consulta fáciles. Las bases de datos más populares son MySQL y PostgreSQL. En la base de datos podrías ingresar datos de venta totales y luego usar un lenguaje llamado Lenguaje de consulta estructurado (SQL- Structured Query Language) para agregar ventas por producto y fecha con el fin de producir un informe.
OpenOffice (a veces llamado OpenOffice.org) y LibreOffice ofrecen una suite ofimática (de oficina) completa, incluyendo una herramienta de dibujo que busca la compatibilidad con Microsoft Office, tanto en términos de características como en formatos de archivo. Estos dos proyectos también sirven de gran ejemplo de cómo influir en política de código abierto.
En 1999 Sun Microsystems adquirió una compañía alemana relativamente desconocida que estaba haciendo una suite ofimática (de oficina) para Linux llamada StarOffice. Pronto después de eso, Sun cambio la marca a OpenOffice y la había liberado bajo una licencia de código abierto. Para complicar más las cosas, StarOffice seguía siendo un producto propietario que se separó de OpenOffice. En 2010 Sun fue adquirido por Oracle, que más tarde entregó el proyecto a la fundación Apache.
Oracle ha tenido una historia pobre de soporte a los proyectos de código abierto que va adquiriendo, así pues pronto después de la adquisición por parte de Oracle el proyecto se bifurcó para convertirse en LibreOffice. En ese momento se crearon dos grupos de personas desarrollando la misma pieza de software. La mayor parte del impulso fue al proyecto LibreOffice, razón por la cual se incluye por defecto en muchas distribuciones de Linux.
Para navegar por la web, los dos principales contendientes son Firefox y Google Chrome. Ambos son navegadores rápidos de código abierto, ricos en funciones y tienen un soporte excelente para desarrolladores web. Estos dos paquetes son un buen ejemplo de cómo la diversidad es buena para el código abierto – mejoras de uno dan estímulo al otro equipo para tratar de mejorar al otro. Como resultado, Internet tiene dos navegadores excelentes que empujan los límites de lo que se puede hacer en la web y el trabajo a través de una variedad de plataformas.
El proyecto Mozilla ha salido también con Thunderbird, un cliente integral de correo electrónico de escritorio. Thunderbird se conecta a un servidor POP o IMAP, muestra el correo electrónico localmente y envía el correo electrónico a través de un servidor SMTP externo.
Linux ofrece una variedad de shells para elegir, en su mayoría difieren en cómo y qué se puede modificar para requisitos particulares y la sintaxis del lenguaje “script” incorporado. Las dos familias principales son Bourne shell y C shell. Bourne shell recibió su nombre de su creador y C shell porque la sintaxis viene prestada del lenguaje C. Como ambos de estos shells fueron inventados en la década de 1970 existen versiones más modernas, el Bourne Again Shell (Bash) y tcsh (tee-cee-shell). Bash es el shell por defecto en la mayoría de los sistemas, aunque casi puedes estar seguro de que tcsh es disponible si lo prefieres.
Otras personas tomaron sus características favoritas de Bash y tcsh y han creado otros shells, como el Korn shell (ksh) y zsh. La elección de los shells es sobre todo personal. Si estás cómodo con Bash entonces puedes operar eficazmente en la mayoría de los sistemas Linux. Después de eso puedes buscar otras vías y probar nuevos shells para ver si ayudan a tu productividad.
Si tienes un sistema Linux necesitarás agregar, quitar y actualizar el software. En cierto momento esto significaba descargar el código fuente, configurarlo, construirlo y copiar los archivos en cada sistema. Afortunadamente, las distribuciones crearon paquetes, es decir copias comprimidas de la aplicación. Un administrador de paquetes se encarga de hacer el seguimiento de que archivos que pertenecen a que paquete, y aun descargando las actualizaciones desde un servidor remoto llamado repositorio. En los sistemas Debian las herramientas incluyen dpkg, apt-get y apt-cache. En los sistemas derivados de Red Hat utilizas rpm y yum. Veremos más de los paquetes más adelante.
Cuando nos referimos a la compra de un software hay tres componentes distintos:
- Propiedad – ¿Quien es el dueño de la propiedad intelectual detrás del software?
- Transferencia de dinero – ¿Cómo pasa el dinero por diferentes manos, si es que pasa?
- Concesión de licencias – ¿Que obtienes? ¿Qué puedes hacer con el software? ¿Puedes utilizarlo sólo en un equipo? ¿Puedes dárselo a otra persona?
Microsoft Corporation posee la propiedad intelectual de Microsoft Windows. La licencia, el CLUF-Contrato de Licencia de Usuario Final (EULA-End User License Agreement) es un documento legal personalizado que debes leer e indicando su aceptación con un clic para que puedas instalar el software. Microsoft posee el código fuente y distribuye sólo copias de binarios a través de canales autorizados. La mayoría de los productos de consumo se les autoriza una instalación de software en una computadora y no se permite hacer otras copias del disco que no sea una copia de seguridad. No puedes revertir el software a código fuente utilizando ingeniería inversa. Pagas por una copia del software con la que obtienes actualizaciones menores, pero no las actualizaciones mayores.
Linux pertenece a Linus Torvalds. Él ha colocado el código bajo una licencia GNU Public License versión 2 (GPLv2). Esta licencia, entre otras cosas, dice que el código fuente debe hacerse disponible a quien lo pida y que puedes hacer cualquier cambio que desees. Una salvedad a esto es que si haces cambios y los distribuyes, debes poner tus cambios bajo la misma licencia para que otros puedan beneficiarse. GPLv2 dice también que no puedes cobrar por distribuir el código fuente a menos que sean tus costos reales de hacerlo (por ejemplo, copiar a medios extraíbles).
En general, si creas algo también consigues el derecho a decidir cómo se utiliza y distribuye. Software libre y de código abierto (FOSS- Free and Open Source Software) se refiere a un tipo de software donde este derecho ha sido liberado y tienes el permiso de ver el código fuente y redistribuirlo. Linus Torvalds ha hecho eso con Linux, aunque creó Linux, no te puede decir que no lo puedes utilizar en tu equipo porque liberó tal derecho a través de la licencia GPLv2.
La concesión de licencias de software es una cuestión política y no debería sorprendernos que haya muchas opiniones diferentes. Las organizaciones han salido con su propia licencia que incorpora su particular punto de vista por lo que es más fácil escoger una licencia existente que idear la tuya propia. Por ejemplo, las universidades como el Instituto Tecnológico de Massachusetts (MIT) y la Universidad de California han sacado sus licencias, ya que tienen proyectos como la Apache Foundation. Además, grupos como la Free Software Foundation han creado sus propias licencias para promover su agenda.
Existen dos grupos que son considerados con la mayor fuerza de influencia en el mundo del código abierto: La Free Software Foundation (FSF) y el Open Source Initiative (OSI).
Términos para lo Mismo
En lugar de afligirse por puntos más sensibles del código abierto frente al Software Libre, la comunidad ha comenzado a referirse a este concepto como Software Libre y de Código Abierto (FOSS). La palabra «libre» puede significar «gratuito como un almuerzo» (sin costo) o «libre como un discurso» (sin restricciones). Esta ambigüedad ha llevado a la inclusión de la palabra libre para referirse a la definición de este último concepto. De esta manera tenemos los términos de software gratuito/libre/de código abierto (FLOSS- Free/Libre/Open Source Software ).
Tales términos son convenientes, pero esconden las diferencias entre las dos escuelas de pensamiento. Por lo menos, si utilizas software FOSS sabes que no tienes que pagar por él y puedes redistribuirlo como quieres.
La organización de Creative Commons (CC) ha creado las Licencias de Creative Commons que tratan de satisfacer las intenciones detrás de las licencias de software libre para entidades no de software. Las licencias CC también pueden utilizarse para restringir el uso comercial si tal es el deseo del titular de los derechos de autor. Las licencias CC son:
- Attribution (CC BY) – al igual que la licencia BSD, puedes utilizar el contenido de la CC para cualquier uso, pero debes acreditar al titular los derechos de autor
- Attribution ShareAlike (CC BY-SA) – una versión copyleft de la licencia de atribución. Los trabajos derivadas deben compartirse bajo la misma licencia, mucho como en los ideales del Software Libre
- Attribution No-Derivs (CC BY-ND) – puedes redistribuir el contenido bajo las mismas condiciones como CC-BY, pero no lo puedes cambiar
- Attribution-NonCommercial (CC BY-NC) – al igual que CC BY, pero no lo puedes utilizar para los fines comerciales
- Attribution-NonCommercial-ShareAlike (CC-BY-NC-SA) – se basa en la licencia CC BY-NC, pero requiere que los cambios se compartan bajo la misma licencia.
- Attribution-NonCommercial-No-Derivs (CC-BY-NC-ND) – compartes el contenido para que se utilice con fines no comerciales, pero la gente no puede cambiar el contenido.
- No Rights Reservados (CC0) – esta es la versión de Creative Commons en el dominio público.
Las licencias anteriores se pueden resumir como ShareAlike o sin restricciones, o si se permite o no el uso comercial o las derivaciones.
El MOTD significa «Message of the Day» (Mensaje del día), y sirve para mostrar a los usuarios un determinado mensaje de advertencia/utilidad a la hora de hacer login en nuestro sistema. Por ejemplo, podemos avisar de un posible corte en el sistema por tareas de mantenimiento ó advertir que toda la actividad será monitorizada y registrada. Se pueden incluir incluso colores, ejecutar scripts y programas que muestren el resultado en el MOTD de forma dinámica cada vez que hagan login en el sistema.
En Ubuntu, gufw es una interfaz gráfica para «Uncomplicated firewall» de Ubuntu.
Las cookies son el mecanismo principal que los sitios web utilizan para darte seguimiento. A veces este seguimiento es bueno, por ejemplo para dar seguimiento de lo que está en tu cesta de compras o para mantenerte conectado cuando regreses al sitio.
El Shell
Un shell es el intérprete que traduce los comandos introducidos por un usuario en acciones a realizar por el sistema operativo. El entorno Linux proporciona muchos tipos diferentes de shells, algunos de los cuales han existido por muchos años.
El shell más comúnmente utilizado para las distribuciones de Linux se llama el BASH shell. Es un shell que ofrece muchas funciones avanzadas, tales como el historial de comandos, que te permite fácilmente volver a ejecutar comandos previamente ejecutados.
El BASH shell tiene también otras funciones populares:
- Scripting: La capacidad de colocar los comandos en un archivo y ejecutar el archivo, resultando en todos los comandos siendo ejecutados. Esta función también tiene algunas características de programación, tales como las instrucciones condicionales y la habilidad de crear funciones (AKA, subrutinas).
- Los Alias: La habilidad de crear «nicknames» (o «sobrenombres» en español) cortos para más comandos más largos.
- Las Variables: Las Variables se utilizan para almacenar información para el BASH shell. Estas variables pueden utilizarse para modificar cómo las funciones y los comandos trabajan y proporcionan información vital sobre el sistema.
Nota: La lista anterior es sólo un breve resumen de algunas de las muchas funciones proporcionadas por el BASH shell.
Los Comandos de Formato
Muchos comandos se pueden utilizar por sí mismos sin más entradas. Algunos comandos requieren entradas adicionales para funcionar correctamente. Esta entrada adicional viene en dos formas: opciones y argumentos.
El formato típico de un comando es el siguiente:
comando [opciones] [argumentos]
Comando ls
En la mayoría de los casos, las opciones pueden utilizarse conjuntamente con otras opciones. Por ejemplo, los comandos ls -l -h o ls -lh listarán los archivos con sus detalles, pero se mostrará el tamaño de los archivos en formato de legibilidad humana en lugar del valor predeterminado (bytes):
sysadmin@localhost:~$ ls -l /usr/bin/perl -rwxr-xr-x 2 root root 10376 Feb 4 2014 /usr/bin/perl sysadmin@localhost:~$ ls -lh /usr/bin/perl -rwxr-xr-x 2 root root 11K Feb 4 2014 /usr/bin/perl sysadmin@localhost:~$
Nota que el ejemplo anterior también demostró cómo se pueden combinar opciones de una letra: -lh . El orden de las opciones combinadas no es importante.
La opción -h también tiene la forma de una palabra completa: --human-readable (–legibilidad-humana).
Las opciones a menudo pueden utilizarse con un argumento. De hecho, algunas de las opciones requieren sus propios argumentos. Puedes utilizar los argumentos y las opciones con el comando ls para listar el contenido de otro directorio al ejecutar el comando ls -l/etc/ppp:
sysadmin@localhost:~$ ls -l /etc/ppp total 0 drwxr-xr-x 1 root root 10 Jan 29 2015 ip-down.d drwxr-xr-x 1 root root 10 Jan 29 2015 ip-up.d sysadmin@localhost:~$
Historial de los Comandos
Si ves un comando que quieres ejecutar en la lista que haya generado el comando history, puedes ejecutar este comando introduciendo el signo de exclamación y luego el número al lado del comando, por ejemplo:
!3
sysadmin@localhost:~$ history
1 date
2 ls
3 cal 5 2015
4 history
sysadmin@localhost:~$ !3
cal 5 2015
May 2015
Su Mo Tu We Th Fr Sa
1 2
3 4 5 6 7 8 9
10 11 12 13 14 15 16
17 18 19 20 21 22 23
24 25 26 27 28 29 30
31
sysadmin@localhost:~$
Algunos ejemplos adicionales del history:
| Ejemplo | Significado |
|---|---|
history 5 | Muestra los últimos cinco comandos de la lista del historial |
!! | Ejecuta el último comando otra vez |
!-5 | Ejecuta el quinto comando desde la parte inferior de la lista de historial |
!ls | Ejecuta el comando ls más reciente |
Variables
Variable HISTSIZE
Para mostrar el valor de una variable, puedes utilizar el comando echo (o «eco» en español). El comando echo se utiliza para mostrar la salida en la terminal; en el ejemplo siguiente, el comando mostrará el valor de la variable HISTSIZE:
sysadmin@localhost:~$ echo $HISTSIZE 1000 sysadmin@localhost:~$
Variable PATH
Una de las variables del shell BASH más importante que hay que entender es la variable PATH.
El término path (o «ruta» en español) se refiere a una lista que define en qué directorios el shell buscará los comandos. Si introduces un comando y recibes el error «command not found» (o «comando no encontrado» en español), es porque el shell BASH no pudo localizar un comando por ese nombre en cualquiera de los directorios en la ruta. El comando siguiente muestra la ruta del shell actual:
sysadmin@localhost:~$ echo $PATH /home/sysadmin/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin: /usr/games sysadmin@localhost:~$
Basado en la anterior salida, cuando intentas ejecutar un comando, el shell primero busca el comando en el directorio /home/sysadmin/bin. Si el comando se encuentra en ese directorio, entonces se ejecuta. Si no es encontrado, el shell buscará en el directorio /usr/local/sbin.
Si el comando no se encuentra en ningún directorio listado en la variable PATH, entonces recibirás un error, command not found:
sysadmin@localhost:~$ zed -bash: zed: command not found sysadmin@localhost:~$
Si en tu sistema tienes instalado un software personalizado, puede que necesites modificar la ruta PATH para que sea más fácil ejecutar estos comandos. Por ejemplo, el siguiente comando agregará el directorio /usr/bin/custom a la variable PATH:
sysadmin@localhost:~$ PATH=/usr/bin/custom:$PATH sysadmin@localhost:~$ echo $PATH /usr/bin/custom:/home/sysadmin/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games sysadmin@localhost:~$
Comando export
Hay dos tipos de variables utilizadas en el shell BASH, la local y la de entorno. Las variables de entorno, como PATH y HOME, las utiliza el BASH al interpretar los comandos y realizar las tareas. Las variables locales son a menudo asociadas con las tareas del usuario y son minúsculas por convención. Para crear una variable local, simplemente introduce:
sysadmin@localhost:~$ variable1='Something'
Para ver el contenido de la variable, te puedes referir a ella iniciando con el signo de $:
sysadmin@localhost:~$ echo $variable1 Something
Para ver las variables de entorno, utiliza el comando env (la búsqueda a través de la salida usando grep, tal como se muestra aquí, se tratará en los capítulos posteriores). En este caso, la búsqueda para variable1 en las variables de entorno resultará en una salida nula:
sysadmin@localhost:~$ env | grep variable1 sysadmin@localhost:~$
Después de exportar variable1 llegará a ser una variable de entorno. Observa que esta vez, se encuentra en la búsqueda a través de las variables de entorno:
sysadmin@localhost:~$ export variable1 sysadmin@localhost:~$ env | grep variable1 variable1=Something
El comando export también puede utilizarse para hacer una variable de entorno en el momento de su creación:
sysadmin@localhost:~$ export variable2='Else' sysadmin@localhost:~$ env | grep variable2 variable2=Else
Para cambiar el valor de una variable de entorno, simplemente omite el $ al hacer referencia a tal valor:
sysadmin@localhost:~$ variable1=$variable1' '$variable2 sysadmin@localhost:~$ echo $variable1 Something Else
Las variables exportadas pueden eliminarse con el comando unset:
sysadmin@localhost:~$ unset variable2
Comando which
Puede haber situaciones donde diferentes versiones del mismo comando se instalan en un sistema o donde los comandos son accesibles para algunos usuarios y a otros no. Si un comando no se comporta como se esperaba o si un comando no está accesible pero debería estarlo, puede ser beneficioso saber donde el shell encuentra tal comando o que versión está utilizando.
Sería tedioso tener que buscar manualmente en cada directorio que se muestra en la variable PATH. En su lugar, puedes utilizar el comando which (o «cuál» en español) para mostrar la ruta completa del comando en cuestión:
sysadmin@localhost:~$ which date /bin/date sysadmin@localhost:~$ which cal /usr/bin/cal sysadmin@localhost:~$
El comando which busca la ubicación de un comando buscando en la variable PATH.
Comando type
El comando type puede utilizarse para determinar la información acerca de varios comandos. Algunos comandos se originan de un archivo específico:
sysadmin@localhost:~$ type which which is hashed (/usr/bin/which)
Esta salida sería similar a la salida del comando which (tal como se explica en el apartado anterior, que muestra la ruta completa del comando):
sysadmin@localhost:~$ which which /usr/bin/which
El comando type también puede identificar comandos integrados en el bash (u otro) shell:
sysadmin@localhost:~$ type echo echo is a shell builtin
En este caso, la salida es significativamente diferente de la salida del comando which:
sysadmin@localhost:~$ which echo /bin/echo
Usando la opción -a, el comando type también puede revelar la ruta de otro comando:
sysadmin@localhost:~$ type -a echo echo is a shell builtin echo is /bin/echo
El comando type también puede identificar a los aliases para otros comandos:
sysadmin@localhost:~$ type ll ll is aliased to `ls -alF' sysadmin@localhost:~$ type ls ls is aliased to `ls --color=auto'
La salida de estos comandos indican que ll es un alias para ls - alF, incluso ls es un alias para ls --color=auto. Una vez más, la salida es significativamente diferente del comando which:
sysadmin@localhost:~$ which ll sysadmin@localhost:~$ which ls /bin/ls
El comando type soporta otras opciones y puede buscar varios comandos al mismo tiempo. Para mostrar sólo una sola palabra que describe al echo, ll, y a los comandos which, utiliza la opción -t:
sysadmin@localhost:~$ type -t echo ll which builtin alias file
Globbing
Los caracteres de globbing se denominan a menudo como «comodines». Estos son símbolos que tienen un significado especial para el shell.
A diferencia de los comandos que ejecutará el shell, u opciones y argumentos que el shell pasará a los comandos, los comodines son interpretados por el mismo shell antes de que intente ejecutar cualquier comando. Esto significa que los comodines pueden utilizarse con cualquier comando.
Asterisco (*)
El asterisco se utiliza para representar cero o más de cualquier carácter en un nombre de archivo. Por ejemplo, supongamos que quieres visualizar todos los archivos en el directorio /etc que empiecen con la letra t:
sysadmin@localhost:~$ echo /etc/t* /etc/terminfo /etc/timezone sysadmin@localhost:~$
El patrón t* significa «cualquier archivo que comienza con el carácter t y tiene cero o más de cualquier carácter después de la letra t«.
Puedes usar el asterisco en cualquier lugar dentro del patrón del nombre de archivo. El siguiente ejemplo coincidirá con cualquier nombre de archivo en el directorio /etc que termina con .d:
sysadmin@localhost:~$ echo /etc/*.d /etc/apparmor.d /etc/bash_completion.d /etc/cron.d /etc/depmod.d /etc/fstab.d /etc/init.d /etc/insserv.conf.d /etc/ld.so.conf.d /etc/logrotate.d /etc/modprobe.d /etc/pam.d /etc/profile.d /etc/rc0.d /etc/rc1.d /etc/rc2.d /etc/rc3.d /etc/rc4.d /etc/rc5.d /etc/rc6.d /etc/rcS.d /etc/rsyslog.d /etc/sudoers.d /etc/sysctl.d /etc/update-motd.d
En el ejemplo siguiente se mostrarán todos los archivos en el directorio /etc que comienzan con la letra r y terminan con .conf:
sysadmin@localhost:~$ echo /etc/r*.conf /etc/resolv.conf /etc/rsyslog.conf
Signo de Interrogación (?)
El signo de interrogación representa cualquier carácter único. Cada carácter de signo de interrogación coincide con exactamente un carácter, nada más y nada menos.
Supongamos que quieres visualizar todos los archivos en el directorio /etc que comienzan con la letra t y que tienen exactamente 7 caracteres después del carácter de t:
sysadmin@localhost:~$ echo /etc/t??????? /etc/terminfo /etc/timezone sysadmin@localhost:~$
Los comodines pueden utilizarse juntos para encontrar patrones más complejos. El comando echo /etc/*???????????????????? imprimirá sólo los archivos del directorio /etc con veinte o más caracteres en el nombre del archivo:
sysadmin@localhost:~$ echo /etc/*???????????????????? /etc/bindresvport.blacklist /etc/ca-certificates.conf sysadmin@localhost:~$
El asterisco y el signo de interrogación también podrían usarse juntos para buscar archivos con extensiones de tres letras ejecutando el comando echo /etc/*.???:
sysadmin@localhost:~$ echo /etc/*.??? /etc/blkid.tab /etc/issue.net sysadmin@localhost:~$
Corchetes [ ]
Los corchetes se utilizan para coincidir con un carácter único representando un intervalo de caracteres que pueden coincidir con los caracteres. Por ejemplo, echo /etc/[gu]* imprimirá cualquier archivo que comienza con el carácter g o u y contiene cero o más caracteres adicionales:
sysadmin@localhost:~$ echo /etc/[gu]* /etc/gai.conf /etc/groff /etc/group /etc/group- /etc/gshadow /etc/gshadow- /etc/ucf.conf /etc/udev /etc/ufw /etc/update-motd.d /etc/updatedb.conf sysadmin@localhost:~$
Los corchetes también pueden ser utilizados para representar un intervalo de caracteres. Por ejemplo, el comando echo /etc/[a-d]* mostrará todos los archivos que comiencen con cualquier letra entre e incluyendo a y d:
sysadmin@localhost:~$ echo /etc/[a-d]* /etc/adduser.conf /etc/adjtime /etc/alternatives /etc/apparmor.d /etc/apt /etc/bash.bashrc /etc/bash_completion.d /etc/bind /etc/bindresvport.blacklist /etc/blkid.conf /etc/blkid.tab /etc/ca-certificates /etc/ca-certificates.conf /etc/calendar /etc/cron.d /etc/cron.daily /etc/cron.hourly /etc/cron.monthly /etc/cron.weekly /etc/crontab /etc/dbus-1 /etc/debconf.conf /etc/debian_version /etc/default /etc/deluser.conf /etc/depmod.d /etc/dpkg sysadmin@localhost:~$
El comando echo /etc/*[0-9]* mostrará todos los archivos que contienen al menos un número:
sysadmin@localhost:~$ echo /etc/*[0-9]* /etc/dbus-1 /etc/iproute2 /etc/mke2fs.conf /etc/python2.7 /etc/rc0.d /etc/rc1.d /etc/rc2.d /etc/rc3.d /etc/rc4.d /etc/rc5.d /etc/rc6.d sysadmin@localhost:~$
El intervalo se basa en el cuadro de texto de ASCII. Esta tabla define una lista de caracteres disponiéndolos en un orden estándar específico. Si proporcionas un orden inválido, no se registrará ninguna coincidencia:
sysadmin@localhost:~$ echo /etc/*[9-0]* /etc/*[9-0]* sysadmin@localhost:~$
Signo de Exclamación (!)
El signo de exclamación se utiliza en conjunto con los corchetes para negar un intervalo. Por ejemplo, el comando echo [!DP]* mostrará cualquier archivo que no comienza con D o P.
Las Comillas
Hay tres tipos de comillas que tienen significado especial para el shell Bash: comillas dobles ", comillas simples ' y comilla invertida `. Cada conjunto de comillas indica al shell que debe tratar el texto dentro de las comillas de una manera distinta a la normal.
Comillas Dobles
Las comillas dobles detendrán al shell de la interpretación de algunos metacaracteres, incluyendo los comodines. Dentro de las comillas dobles, el asterisco es sólo un asterisco, un signo de interrogación es sólo un signo de interrogación y así sucesivamente. Esto significa que cuando se utiliza el segundo comando echo más abajo, el shell BASH no convierte el patrón de globbing en nombres de archivos que coinciden con el patrón:
sysadmin@localhost:~$ echo /etc/[DP]* /etc/DIR_COLORS /etc/DIR_COLORS.256color /etc/DIR_COLORS.lightbgcolor /etc/PackageKit sysadmin@localhost:~$ echo "/etc/[DP]*" /etc/[DP]* sysadmin@localhost:~$
Esto es útil cuando quieres mostrar algo en la pantalla, lo que suele ser un carácter especial para el shell:
sysadmin@localhost:~$ echo "The glob characters are *, ? and [ ]" The glob characters are *, ? and [ ] sysadmin@localhost:~$
Las comillas dobles todavía permiten la sustitución de comando, sustitución de variable y permiten algunos metacaracteres de shell. Por ejemplo, en la siguiente demostración, notarás que el valor de la variable PATH es desplegada:
sysadmin@localhost:~$ echo "The path is $PATH" The path is /usr/bin/custom:/home/sysadmin/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games sysadmin@localhost:~$
Comillas Simples
Las comillas simples evitan que el shell interprete algunos caracteres especiales. Esto incluye comodines, variables, sustitución de comando y otro metacarácter.
Por ejemplo, si quieres que el carácter $ simplemente signifique un $, en lugar de actuar como un indicador del shell para buscar el valor de una variable, puedes ejecutar el segundo comando que se muestra a continuación:
sysadmin@localhost:~$ echo The car costs $100 The car costs 00 sysadmin@localhost:~$ echo 'The car costs $100' The car costs $100 sysadmin@localhost:~$
Barra Diagonal Inversa (\)
Puedes utilizar una técnica alternativa para citar un carácter con comillas simples. Por ejemplo, supón que quieres imprimir lo siguiente: “The services costs $100 and the path is $PATH«. Si pones esto entre las comillas dobles, $1 y $PATH se consideran variables. Si pones esto entre las comillas simples, $1 y $PATH no son variables. Pero ¿qué pasa si quieres tener $PATH tratado como una variable y no a $1?
Si colocas una barra diagonal invertida \ antes del otro carácter, tratará al otro carácter como un carácter de «comillas simples». El tercer comando más abajo muestra cómo utilizar el carácter \, mientras que los otros dos muestran cómo las variables serían tratadas si las pones entre las comillas dobles y simples:
sysadmin@localhost:~$ echo "The service costs $100 and the path is $PATH" The service costs 00 and the path is /usr/bin/custom:/home/sysadmin/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games sysadmin@localhost:~$ echo 'The service costs $100 and the path is $PATH' The service costs $100 and the path is $PATH sysadmin@localhost:~$ echo The service costs \$100 and the path is $PATH The service costs $100 and the path is /usr/bin/custom:/home/sysadmin/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games sysadmin@localhost:~$
Comilla Invertida
Las comillas invertidas se utilizan para especificar un comando dentro de un comando, un proceso de sustitución del comando. Esto permite un uso muy potente y sofisticado de los comandos.
Aunque puede sonar confuso, un ejemplo debe hacer las cosas más claras. Para empezar, fíjate en la salida del comando date:
sysadmin@localhost:~$ date Mon Nov 2 03:35:50 UTC 2015
Ahora fíjate en la salida de la línea de comandos echo Today is date (o «eco La fecha de hoy es» en español):
sysadmin@localhost:~$ echo Today is date Today is date sysadmin@localhost:~$
En el comando anterior la palabra date (o «fecha» en español) es tratada como texto normal y el shell simplemente pasa date al comando echo. Pero, probablemente quieras ejecutar el comando date y tener la salida de ese comando enviado al comando echo. Para lograr esto, deberás ejecutar la línea de comandos echo Today is `date`:
sysadmin@localhost:~$ echo Today is `date` Today is Mon Nov 2 03:40:04 UTC 2015 sysadmin@localhost:~$
Instrucciones de Control
Las instrucciones de control te permiten utilizar varios comandos a la vez o ejecutar comandos adicionales, dependiendo del éxito de un comando anterior. Normalmente estas instrucciones de control se utilizan en scripts o secuencias de comandos, pero también pueden ser utilizadas en la línea de comandos.
Punto y Coma
El punto y coma puede utilizarse para ejecutar varios comandos, uno tras otro. Cada comando se ejecuta de forma independiente y consecutiva; no importa el resultado del primer comando, el segundo comando se ejecutará una vez que el primero haya terminado, luego el tercero y así sucesivamente.
Por ejemplo, si quieres imprimir los meses de enero, febrero y marzo de 2015, puedes ejecutar cal 1 2015; cal 2 2015; cal 3 2015 en la línea de comandos:
sysadmin@localhost:~$ cal 1 2015; cal 2 2015; cal 3 2015
January 2015
Su Mo Tu We Th Fr Sa
1 2 3
4 5 6 7 8 9 10
11 12 13 14 15 16 17
18 19 20 21 22 23 24
25 26 27 28 29 30 31
February 2015
Su Mo Tu We Th Fr Sa
1 2 3 4 5 6 7
8 9 10 11 12 13 14
15 16 17 18 19 20 21
22 23 24 25 26 27 28
March 2015
Su Mo Tu We Th Fr Sa
1 2 3 4 5 6 7
8 9 10 11 12 13 14
15 16 17 18 19 20 21
22 23 24 25 26 27 28
29 30 31
Ampersand Doble (&&)
El símbolo de ampersand doble && actúa como un operador «y» lógico. Si el primer comando tiene éxito, entonces el segundo comando (a la derecha de la &&) también se ejecutará. Si el primer comando falla, entonces el segundo comando no se ejecutará.
Para entender mejor como funciona esto, consideremos primero el concepto de fracaso y éxito para los comandos. Los comandos tienen éxito cuando algo funciona bien y fallan cuando algo sale mal. Por ejemplo, considera la línea de comandos ls /etc/xml. El comando tendrá éxito si el directorio /etc/xml es accesible y fallará cuando no es accesible.
Por ejemplo, el primer comando tendrá éxito porque el directorio /etc/xml existe y es accesible mientras que el segundo comando fallará porque no hay un directorio /junk:
sysadmin@localhost:~$ ls /etc/xml catalog catalog.old xml-core.xml xml-core.xml.old sysadmin@localhost:~$ ls /etc/junk ls: cannot access /etc/junk: No such file or directory sysadmin@localhost:~$
La manera en que usarías el éxito o fracaso del comando ls junto con && sería ejecutando una línea de comandos como la siguiente:
sysadmin@localhost:~$ ls /etc/xml && echo success catalog catalog.old xml-core.xml xml-core.xml.old success sysadmin@localhost:~$ ls /etc/junk && echo success ls: cannot access /etc/junk: No such file or directory sysadmin@localhost:~$
En el primer ejemplo arriba, el comando echo fue ejecutado, porque tuvo éxito el comando ls. En el segundo ejemplo, el comando echo no fue ejecutado debido a que el comando ls falló.
Línea Vertical Doble
La línea vertical doble || es un operador lógico «o». Funciona de manera similar a &&; dependiendo del resultado del primer comando, el segundo comando se ejecutará o será omitido.
Con la línea vertical doble, si el primer comando se ejecuta con éxito, el segundo comando es omitido. Si el primer comando falla, entonces se ejecutará el segundo comando. En otras palabras, esencialmente estás diciendo al shell, «O bien ejecuta este primer comando o bien el segundo».
En el ejemplo siguiente, el comando echo se ejecutará sólo si falla el comando ls:
sysadmin@localhost:~$ ls /etc/xml || echo failed catalog catalog.old xml-core.xml xml-core.xml.old sysadmin@localhost:~$ ls /etc/junk || echo failed ls: cannot access /etc/junk: No such file or directory failed sysadmin@localhost:~$
Ayuda para el comando man -h
| Comando | Función |
|---|---|
| Return (o Intro) | Bajar una línea |
| Space (o Espacio) | Bajar una página |
/term(o /término | Buscar un término |
| n | Buscar el siguiente elemento de la búsqueda |
| N | Buscar el elemento anterior de la búsqueda |
| 1G | Ir a Inicio |
| G | Ir a la final |
| h | Mostrar ayuda |
| q | Cerrar página man |
Para considerar:
Por defecto, hay nueve secciones de las páginas man:
- Programas ejecutables o comandos del shell
- Llamadas del sistema (funciones proporcionados por el kernel)
- Llamadas de la librería (funciones dentro de las librerías de los programas)
- Archivos especiales (generalmente se encuentran en
/dev) - Formatos de archivo y convenciones, por ejemplo
/etc/passwd - Juegos
- Otros (incluyendo paquetes macro y convenciones), por ejemplo,
man(7),groff(7) - Comandos de administración de sistema (generalmente sólo para el root)
- Rutinas del kernel [No estándar]
Especificar una Sección
En algunos casos, necesitarás especificar la sección para visualizar la página man correcta. Esto es necesario porque a veces habrá páginas man con el mismo nombre en diferentes secciones.
Por ejemplo, hay un comando llamado passwd que permite cambiar tu contraseña. También hay un archivo llamado passwd que almacena la información de la cuenta. Ambos, el comando y el archivo tienen una página man.
El comando passwd es un comando de «user» (o «usuario» en español), por lo que el comando man passwd mostrará la página man para el comando passwd por defecto:
PASSWD(1) User Commands PASSWD(1)
Para especificar una sección diferente, proporciona el número de la sección como el primer argumento del comando man. Por ejemplo, el comando man 5 passwd buscará la página man de passwd sólo en la sección 5:
PASSWD(5) File Formats and Conversions PASSWD(5)
Buscar las Secciones
A veces no es claro en qué sección se almacena una página man. En estos casos, puedes buscar una página man por nombre.
La opción -f para el comando man mostrará páginas que coinciden, o parcialmente coinciden, con un nombre específico y provee una breve descripción de cada página man:
sysadmin@localhost:~$ man -f passwd passwd (5) - the password file passwd (1) - change user password passwd (1ssl) - compute password hashes sysadmin@localhost:~$
Ten en cuenta que en la mayoría de las distribuciones de Linux, el comando whatis hace lo mismo que el comando man -f. En esas distribuciones, ambos comandos producen la misma salida.
Buscar Páginas man por una Palabra Clave
Desafortunadamente, no siempre te acordarás del nombre exacto de la página man que quieres ver. En estos casos puedes buscar páginas man que coincidan con una palabra clave mediante el uso de la opción -k del comando man.
Por ejemplo, ¿qué pasa si quieres ver una página que muestra cómo cambiar la contraseña, pero no recuerdas el nombre exacto? Puedes ejecutar el comando man -k password:
sysadmin@localhost:~$ man -k passwd chgpasswd (8) - update group passwords in batch mode chpasswd (8) - update passwords in batch mode fgetpwent_r (3) - get passwd file entry reentrantly getpwent_r (3) - get passwd file entry reentrantly gpasswd (1) - administer /etc/group and /etc/gshadow pam_localuser (8) - require users to be listed in /etc/passwd passwd (1) - change user password passwd (1ssl) - compute password hashes passwd (5) - the password file passwd2des (3) - RFS password encryption update-passwd (8) - safely update /etc/passwd, /etc/shadow and /etc/group sysadmin@localhost:~$
Al utilizar esta opción puedes recibir una gran cantidad de salidas. El comando anterior, por ejemplo, dió salida a 60 resultados.
Recuerda que hay miles de páginas man, así que cuando buscas por una palabra clave, sé tan específico como sea posible. Usando una palabra genérica, como «the» (o «el/la» en español), podría resultar en cientos o incluso miles de resultados.
Ten en cuenta que en la mayoría de las distribuciones de Linux, el comando apropos hace lo mismo que el comando man -k. En esas distribuciones, ambas producen la misma salida.
Visualizar la Documentación Info para un Comando
Para visualizar la documentación info de un comando, ejecuta el comando info command (reemplaza command con el nombre del comando sobre cuál buscas la información). Por ejemplo, info ls:
Cambiando de Posición mientras se Visualiza un Documento info
Igual que el comando man, puedes obtener un listado de comandos de movimiento escribiendo la letra h al leer la documentación info:
a tabla siguiente proporciona un resumen de los comandos útiles:
| Comando | Función |
|---|---|
| Flecha abajo ↓ | Bajar una línea |
| Espacio | Bajar una página |
| s | Buscar un término |
| [ | Ir al nodo anterior |
| ] | Vaya al siguiente nodo |
| u | Subir un nivel |
| TABULADOR | Saltar al siguiente hipervínculo |
| INICIO | Ir a inicio |
| FIN | Ir al final |
| h | Mostrar ayuda |
| L | Cerrar la página de ayuda |
| q | Cerrar el comando info |
Utilizar la opción –help
Muchos comandos te proporcionan información básica, muy similar a la sección SYNOPSIS que aparece en las páginas man, al aplicar la opción --help (o «ayuda» en español) al comando. Esto es útil para aprender el uso básico de un comando
Documentación Adicional del Sistema
En la mayoría de los sistemas, existe un directorio donde se encuentra la documentación adicional. A menudo se trata de una ubicación donde los proveedores que crean software adicional (de terceros) almacenan sus archivos de documentación.
Por lo general, se trata de una ubicación donde los administradores del sistema irán a aprender cómo configurar servicios de software más complejos. Sin embargo, los usuarios regulares a veces también encuentran esta documentación útil.
Estos archivos de documentación se suelen llamar archivos «readme» (o «leeme» en español), ya que los archivos tienen nombres como README o readme.txt. La ubicación de estos archivos puede variar según la distribución que estés utilizando. Ubicaciones típicas incluyen /usr/share/doc y /usr/doc.
¿Dónde están ubicados los comandos?
Para buscar la ubicación de un comando o de las páginas man para un comando, utiliza el comando whereis (o «dónde está» en español). Este comando busca los comandos, archivos de código fuente y las páginas man en las ubicaciones específicas donde estos archivos se almacenan normalmente:
sysadmin@localhost:~$ whereis ls ls: /bin/ls /usr/share/man/man1/ls.1.gz sysadmin@localhost:~$
Las páginas man se suelen distinguir fácilmente entre los comandos ya que normalmente están comprimidos con un comando llamado gzip, dando por resultado un nombre de archivo que termina en .gz.
Encontrar Cualquier Archivo o Directorio
El comando whereis está diseñado para encontrar de manera específica las páginas man y los comandos. Si bien esto es útil, hay veces en las que quieras encontrar un archivo o directorio, no sólo archivos de comandos o páginas mas.
Para encontrar cualquier archivo o directorio, puede utilizar el comando locate (o «localizar» en español). Este comando buscará en una base de datos de todos los archivos y directorios que estaban en el sistema cuando se creó la base de datos. Por lo general, el comando que genera tal base de datos se ejecuta por la noche.
Los archivos que creaste hoy normalmente no los vas a poder buscar con el comando locate. Si tienes acceso al sistema como usuario root (con la cuenta del administrador de sistema), puede actualizar manualmente la base de datos locate ejecutando el comando updatedb. Los usuarios regulares no pueden actualizar el archivo de base de datos.
También ten en cuenta que cuando utilizas el comando locate como un usuario normal, tu salida puede ser limitada debido a los permisos. En general, si no tienes acceso a un archivo o directorio en el sistema de ficheros debido a los permisos, el comando locate no devolverá esos nombres. Esta es una característica de seguridad diseñada para evitar que los usuarios «exploren» el sistema de ficheros utilizando el comando locate. El usuario root puede buscar cualquier archivo en la base de datos con el comando locate.
Contar el Número de Archivos
La salida del comando locate puede ser bastante grande. Cuando buscas un nombre de archivo, como passwd, el comando locate producirá cada archivo que contiene la cadena passwd, no sólo los archivos passwd.
En muchos casos, puede que quieras empezar listando cuántos archivos coincidirán. Lo puedes hacer mediante la opción -c del comando locate:
sysadmin@localhost:~$ locate -c passwd 97 sysadmin@localhost:~$
Capítulo 6
Igual que Windows, la estructura de directorios de Linux tiene un nivel superior, sin embargo no se llama Este Equipo, sino directorio raíz y su símbolo es el carácter / . También, en Linux no hay unidades; cada dispositivo físico es accesible bajo un directorio, no una letra de unidad. Una representación visual de una estructura de directorios típica de Linux:
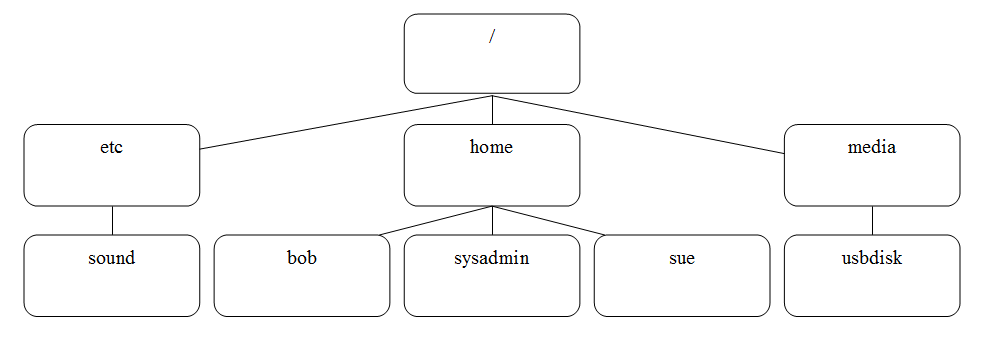
La mayoría de los usuarios de Linux denominan esta estructura de directorios el sistema de archivos.
Para considerar:
El directorio /etc originalmente significaba «etcetera» en la documentación temprana de Bell Labs y solía contener archivos que no pertenecían a ninguna ubicación. En las distribuciones modernas de Linux, el directorio /etc por lo general contiene los archivos de configuración estática como lo define por el Estándar de Jerarquía de Archivos (o «FHS», del inglés «Files Hierarchy Standard»).
Una ruta de acceso te permite especificar la ubicación exacta de un directorio. Para el directorio sound la ruta de acceso sería /etc/sound. El primer carácter / representa el directorio root (o «raíz» en español), mientras que cada siguiente carácter / se utiliza para separar los nombres de directorio.
Este tipo de ruta se llama la ruta absoluta (o «aboslute path» en inglés). Con una ruta absoluta, siempre proporcionas direcciones a un directorio (o un archivo) a partir de la parte superior de la estructura de directorios, el directorio root.
Lista de Colores
Hay muchos tipos de archivos en Linux. Según vayas aprendiendo más sobre Linux, descubrirás muchos de estos tipos. A continuación tenemos un breve resumen de algunos de los tipos de archivo más comunes:
| Tipo | Descripción |
|---|---|
| plain file (o «archivo simple» en español) | Un archivo que no es un tipo de archivo especial; también se llama un archivo normal |
| directory (o «directorio» en español) | Un directorio de archivos (contiene otros archivos) |
| executable (o «ejecutable» en español) | Un archivo que se puede ejecutar como un programa |
| symbolic link | Un archivo que apunta a otro archivo (o «enlace simbólico» en español) |
En muchas distribuciones de Linux, las cuentas de usuario regulares son modificadas de tal manera que el comando ls muestre los nombres de archivo, codificados por colores según el tipo de archivo. Por ejemplo, los directorios pueden aparecer en azul, archivos ejecutables pueden verse en verde, y enlaces simbólicos pueden ser visualizados en cian (azul claro).
Esto no es un comportamiento normal para el comando ls, sino algo que sucede cuando se utiliza la opción --color para el comando ls. La razón por la que el comando ls parece realizar automáticamente estos colores, es que hay un alias para el comando ls para que se ejecute con la opción --color:
sysadmin@localhost:~$ alias alias egrep='egrep --color=auto' alias fgrep='fgrep --color=auto' alias grep='grep --color=auto' alias l='ls -CF' alias la='ls -A' alias ll='ls -alF' alias ls='ls --color=auto' sysadmin@localhost:~$
Como puedes ver en la salida anterior, cuando se ejecuta el comando ls, en realidad se ejecuta el comando ls --color=auto.
En algunos casos, puede que no quieras ver todos los colores (a veces te pueden distraer un poco). Para evitar el uso de los alias, coloca un carácter de barra invertida \ antes de tu comando:
sysadmin@localhost:~$ ls Desktop Documents Downloads Music Pictures Public Templates Videos sysadmin@localhost:~$ \ls Desktop Documents Downloads Music Pictures Public Templates Videos sysadmin@localhost:~$
Lista de los Archivos Ocultos
Cuando utilizas el comando ls para mostrar el contenido de un directorio, no todos los archivos se muestran automáticamente. El comando ls no muestra los archivos ocultos de manera predeterminada. Un archivo oculto es cualquier archivo (o directorio) que comienza con un punto ..
Para mostrar todos los archivos, incluyendo los archivos ocultos, utiliza la opción -a para el comando ls.
Listado con Visualización Larga
Existe información sobre cada archivo, llamada metadata (o «metadatos» en español), y visualizarla a veces resulta útil. Esto puede incluir datos de quién es el dueño de un archivo, el tamaño de un archivo y la última vez que se modificó el contenido de un archivo. Puedes visualizar esta información mediante el uso de la opción -l para el comando ls.

Para cambiar el tamaño de un archivo y que no se vea en bytes, sino como megabytes o gigabytes. Para lograr esto, añade la opción -h al comando ls:
sysadmin@localhost:~$ ls -lh /usr/bin/omshell -rwxr-xr-c 1 root root 1.5M Oct 9 2012 /usr/bin/omshell sysadmin@localhost:~$
Importante: Debes utilizar la opción -h junto con la opción -l.
Lista de Directorios
Cuando se utiliza el comando ls -d, se refiere al directorio actual y no al contenido dentro de él. Sin otras opciones, es algo sin sentido, aunque es importante tener en cuenta que al directorio actual siempre se refiere con un solo punto (.):
sysadmin@localhost:~$ ls -d .
Para utilizar el comando ls -d de una manera significativa tienes que añadir la opción -l. En este caso, ten en cuenta que el primer comando muestra los detalles de los contenidos en el directorio /home/sysadmin, mientras que el segundo lista el directorio /home/sysadmin.
sysadmin@localhost:~$ ls -l total 0 drwxr-xr-x 1 sysadmin sysadmin 0 Apr 15 2015 Desktop drwxr-xr-x 1 sysadmin sysadmin 0 Apr 15 2015 Documents drwxr-xr-x 1 sysadmin sysadmin 0 Apr 15 2015 Downloads drwxr-xr-x 1 sysadmin sysadmin 0 Apr 15 2015 Music drwxr-xr-x 1 sysadmin sysadmin 0 Apr 15 2015 Pictures drwxr-xr-x 1 sysadmin sysadmin 0 Apr 15 2015 Public drwxr-xr-x 1 sysadmin sysadmin 0 Apr 15 2015 Templates drwxr-xr-x 1 sysadmin sysadmin 0 Apr 15 2015 Videos drwxr-xr-x 1 sysadmin sysadmin 420 Apr 15 2015 test sysadmin@localhost:~$ ls -ld drwxr-xr-x 1 sysadmin sysadmin 224 Nov 7 17:07 . sysadmin@localhost:~$
Observa el punto solo al final de la segunda lista larga. Esto indica que el directorio actual está en la lista y no el contenido.
Ordenar un Listado
De forma predeterminada, el comando ls ordena los archivos alfabéticamente por nombre de archivo. A veces, puede ser útil ordenar los archivos utilizando diferentes criterios.
Para ordenar los archivos por tamaño, podemos utilizar la opción -S.
Listado con Globs
¿Por qué ésto es un problema al utilizar los globs? Considera el siguiente resultado:
sysadmin@localhost:~$ ls /etc/e* /etc/encript.cfg /etc/environment /etc/ethers /etc/event.d /etc/exports /etc/event.d: ck-log-system-restart ck-log-system-start ck-log-system-stop sysadmin@localhost:~$
Como puedes ver, cuando el comando ls ve un nombre de archivo como argumento, sólo muestra el nombre del archivo. Sin embargo, para cualquier directorio, mostrará el contenido del directorio, y no sólo el nombre del directorio.
Esto se vuelve aún más confuso en una situación como la siguiente:
sysadmin@localhost:~$ ls /etc/ev* ck-log-system-restart ck-log-system-start ck-log-system-stop sysadmin@localhost:~$
En el ejemplo anterior, parece que el comando ls es simplemente incorrecto. Pero lo que realmente sucedió es que lo único que coincide con el glob etc/ev * es el directorio /etc/event.d. Por lo tanto, el comando ls muestra sólo los archivos en ese directorio.
Hay una solución simple a este problema: al utilizar los argumentos glob con el comando ls, utiliza siempre la opción -d. Cuando utilizas la opción -d, el comando ls no muestra el contenido de un directorio, sino más bien el nombre del directorio:
sysadmin@localhost:~$ ls -d /etc/e* /etc/encript.cfg /etc/environment /etc/ethers /etc/event.d /etc/exports sysadmin@localhost:~$
Copiar los Archivos
El comando cp se utiliza para copiar los archivos. Requiere especificar un origen y un destino. La estructura del comando es la siguiente:
cp [fuente] [destino]
El Modo Verbose
La opción -v hará que el comando cp produzca la salida en caso de ser exitoso. La opción -v se refiere al comando verbose:
sysadmin@localhost:~$ cp -v /etc/hosts ~ `/etc/hosts' -> `/home/sysadmin/hosts' sysadmin@localhost:~$
Cuando el destino es un directorio, el nuevo archivo resultante tendrá el mismo nombre que el archivo original. Si quieres que el nuevo archivo tenga un nombre diferente, debes proporcionar el nuevo nombre como parte del destino:
sysadmin@localhost:~$ cp /etc/hosts ~/hosts.copy sysadmin@localhost:~$ ls Desktop Downloads Pictures Templates hosts Documents Music Public Videos hosts.copy sysadmin@localhost:~$
Evitar Sobrescribir los Datos
El comando cp puede ser destructivo para los datos si el archivo de destino ya existe. En el caso donde el archivo de destino existe, el comando cp sobreescribe el contenido del archivo existente con el contenido del archivo fuente. Para ilustrar este problema, primero se crea un nuevo archivo en el directorio home sysadmin copiando un archivo existente:
sysadmin@localhost:~$ cp /etc/skel/.bash_logout ~/example.txt sysadmin@localhost:~$
Visualiza la salida del comando ls para ver el archivo y visualiza el contenido del archivo utilizando el comando more.
La opción -i requiere respuesta y o n para cada copia que podría sobrescribir el contenido de un archivo existente. Esto puede ser tedioso cuando se sobrescribe un grupo, como se muestra en el siguiente ejemplo:
sysadmin@localhost:~$ cp -i /etc/skel/.* ~ cp: omitting directory `/etc/skel/.' cp: omitting directory `/etc/skel/..' cp: overwrite `/home/sysadmin/.bash_logout'? n cp: overwrite `/home/sysadmin/.bashrc'? n cp: overwrite `/home/sysadmin/.profile'? n cp: overwrite `/home/sysadmin/.selected_editor'? n sysadmin@localhost:~$
Como puedes ver en el ejemplo anterior, el comando cp intentó sobrescribir los cuatro archivos existentes, obligando al usuario a responder a tres prompts. Si esta situación ocurriera para 100 archivos, puede resultar muy molesto rápidamente.
Si quieres contestar automáticamente n para cada prompt, utiliza la opción -n. En esencia, significa «sin sobreescribir».
Copiar los Directorios
En un ejemplo anterior se dieron mensajes de error cuando el comando cp intentó copiar los directorios:
sysadmin@localhost:~$ cp -i /etc/skel/.* ~ cp: omitting directory `/etc/skel/.' cp: omitting directory `/etc/skel/..' cp: overwrite `/home/sysadmin/.bash_logout'? n cp: overwrite `/home/sysadmin/.bashrc'? n cp: overwrite `/home/sysadmin/.profile'? n cp: overwrite `/home/sysadmin/.selected_editor'? n sysadmin@localhost:~$
Donde la salida dice ...omitting directory... (o «omitiendo directorio» en español), el comando cp está diciendo que no puede copiar este artículo porque el comando no copia los directorios por defecto. Sin embargo, la opción -r del comando cp copiará ambos, los archivos y los directorios.
Ten cuidado con esta opción: se copiará la estructura completa del directorio. ¡Esto podría resultar en copiar muchos archivos y directorios!
Mover los Archivos
Para mover un archivo, utiliza el comando mv. La sintaxis del comando mv es muy parecida al comando cp:
mv [fuente] [destino]
Renombrar los Archivos
El comando mv no sólo se utiliza para mover un archivo, sino también cambiar el nombre de un archivo. Por ejemplo, los siguientes comandos cambiarán el nombre del archivo newexample.txt a myexample.txt:
sysadmin@localhost:~$ cd Videos sysadmin@localhost:~/Videos$ ls hosts newexample.txt sysadmin@localhost:~/Videos$ mv newexample.txt myexample.txt sysadmin@localhost:~/Videos$ ls hosts myexample.txt sysadmin@localhost:~/Videos$
Piensa en el ejemplo anterior del mv que significa «mover el archivo newexample.txt desde el directorio actual de regreso al directorio actual y denominar el nuevo archivo como myexample.txt».
Opciones Adicionales del mv
Igual al comando cp, el comando mv proporciona las siguientes opciones:
| Opción | Significado |
|---|---|
-i | Movimiento interactivo: pregunta si un archivo debe sobrescribirse. |
-n | No sobrescribir el contenido de los archivos de destino |
-v | Verbose: muestra el movimiento resultante |
Importante: Aquí no hay ninguna opción -r, ya que el comando mv moverá los directorios de forma predeterminada.
Eliminar los Archivos
Para borrar un archivo, utiliza el comando de rm:
sysadmin@localhost:~$ ls Desktop Downloads Pictures Templates sample Documents Music Public Videos sysadmin@localhost:~$ rm sample sysadmin@localhost:~$ ls Desktop Documents Downloads Music Pictures Public Templates Videos sysadmin@localhost:~$
Ten en cuenta que el archivo fue borrado sin hacer preguntas. Esto podría causar problemas al borrar varios archivos usando los caracteres glob, por ejemplo: rm *.txt. Ya que estos archivos son borrados sin proporcionar una pregunta, un usuario podría llegar a borrar archivos que no quería eliminar.
Además, los archivos se eliminan permanentemente. No hay ningún comando para recuperar un archivo y no hay «papelera de reciclaje» («trash can» en inglés) desde la que puedas recuperar los archivos eliminados. Como precaución, los usuarios deben utilizar la opción -i al eliminar varios archivos.
Eliminar los Directorios
Puedes borrar los directorios con el comando rm. Sin embargo, si utilizas el comando rm por defecto (sin opciones), éste no eliminará un directorio:
sysadmin@localhost:~$ rm Videos rm: cannot remove `Videos': Is a directory sysadmin@localhost:~$
Si quieres eliminar un directorio, utiliza la opción -r con el comando rm:
sysadmin@localhost:~$ ls Desktop Downloads Pictures Templates sample.txt Documents Music Public Videos sysadmin@localhost:~$ rm -r Videos sysadmin@localhost:~$ ls Desktop Documents Downloads Music Pictures Public Templates sample.txt sysadmin@localhost:~$
Importante: Cuando un usuario elimina un directorio, todos los archivos y subdirectorios se eliminan sin proporcionar pregunta interactiva. Lo mejor es utilizar la opción -i con el comando rm.
También puedes borrar un directorio con el comando rmdir, pero sólo si el directorio está vacío.
Comprimir los Archivos
Comprimiendo los archivos los hace más pequeños eliminando la duplicación en un archivo y guardándolo de tal manera que el archivo se pueda restaurar. Un archivo de texto legible podría reemplazar palabras usadas con frecuencia por algo más pequeño, o una imagen con un fondo sólido podría representar manchas de ese color por un código. Generalmente no usas la versión comprimida del archivo, más bien lo descomprimes antes de usar. El algoritmo de compresión es un procedimiento con el que la computadora codifica el archivo original y como resultado lo hace más pequeño. Los científicos informáticos investigan estos algoritmos y elaboran mejores, que pueden trabajar más rápido o hacer más pequeño el archivo de entrada.
Cuando se habla de compresión, existen dos tipos:
- Lossless (o «sin pérdida» en español): No se elimina ninguna información del archivo. Comprimir un archivo y descomprimirlo deja algo idéntico al original.
- Lossy (o «con pérdida» en español): Información podría ser retirada del archivo cuando se comprime para que al descomprimir el archivo de lugar a un archivo que es un poco diferente que el original. Por ejemplo, una imagen con dos tonos de verde sutilmente diferentes podría hacerse más pequeña por tratar esos dos tonos como uno. De todos modos, el ojo no puede reconocer la diferencia.
Linux proporciona varias herramientas para comprimir los archivos, la más común es gzip. A continuación te mostraremos un archivo de registro antes y después de la compresión.
bob:tmp $ ls -l access_log* -rw-r--r-- 1 sean sean 372063 Oct 11 21:24 access_log bob:tmp $ gzip access_log bob:tmp $ ls -l access_log* -rw-r--r-- 1 sean sean 26080 Oct 11 21:24 access_log.gz
En el ejemplo anterior hay un archivo llamado access_log que tiene 372,063 bytes. El archivo se comprime invocando el comando gzip con el nombre del archivo como el único argumento. Al finalizar el comando su tarea, el archivo original desaparece y una versión comprimida con una extensión de archivo .gz se queda en su lugar. El tamaño del archivo es ahora 26,080 bytes, dando una relación de compresión de 14:1, que es común en el caso de los archivos de registro.
El comando gzip te dará esta información si se lo pides utilizando el parámetro –l tal como se muestra aquí:
bob:tmp $ gzip -l access_log.gz
compressed uncompressed ratio uncompressed_name
26080 372063 93.0% access_log
Aquí puedes ver que se da el porcentaje de compresión de 93%, lo inverso de la relación 14:1, es decir, 13/14. Además, cuando el archivo se descomprime, se llamará access_log.
bob:tmp $ gunzip access_log.gz bob:tmp $ ls -l access_log* -rw-r--r-- 1 sean sean 372063 Oct 11 21:24 access_log
Lo contrario del comando gzip es el comando gunzip. Por otra parte, gzip –d hace la misma cosa (gunzip es sólo un script que invoca el comando gzip con los parámetros correctos). Cuando el comando gunzip termine su tarea, podrás ver que el archivo access_log vuelve a su tamaño original.
Gzip puede también actuar como un filtro que no lee ni escribe nada en el disco sino recibe datos a través de un canal de entrada y los escribe a un canal de salida. .
bob:tmp $ mysqldump -A | gzip > database_backup.gz
bob:tmp $ gzip -l database_backup.gz
compressed uncompressed ratio uncompressed_name
76866 1028003 92.5% database_backup
El comando mysqldump – A da salidas a los contenidos de las bases de datos de MySQL locales a la consola. El carácter | (barra vertical) dice «redirigir la salida del comando anterior en la entrada del siguiente». El programa para recibir la salida es gzip, que reconoce que no se dieron nombres de archivo por lo que debe funcionar en modo de barra vertical. Por último, > database_backup.gz significa «redirigir la salida del comando anterior en un archivo llamado database_backup.gz. La inspección de este archivo con gzip –l muestra que la versión comprimida es un 7.5% del tamaño original, con la ventaja agregada de que el archivo más grande jamás tuvo que ser escrito a disco.
Hay otro par de comandos que operan prácticamente idénticamente al gzip y gunzip. Éstos son el bzip2 y bunzip2. Las utilidades del bzip utilizan un algoritmo de compresión diferente (llamado bloque de clasificación de Burrows-Wheeler frente a la codificación Lempel-Ziv que utiliza gzip) que puede comprimir los archivos más pequeños que un gzip a costa de más tiempo de CPU. Puedes reconocer estos archivos porque tienen una extensión .bz o .bz2 en vez de .gz.
Empaquetando Archivos
Si quieres enviar varios archivos a alguien, podrías comprimir cada uno individualmente. Tendrías una cantidad más pequeña de datos en total que si enviaras los archivos sin comprimir, pero todavía tendrás que lidiar con muchos archivos al mismo tiempo.
El empacamiento de archivos es la solución a este problema. La utilidad tradicional de UNIX para archivar los ficheros es la llamada tar, que es una abreviación de TApe aRchive (o «archivo de cinta» en español). Tar era utilizado para transmitir muchos archivos a una cinta para copias de seguridad o transferencias de archivos. Tar toma varios archivos y crea un único archivo de salida que se puede dividir otra vez en los archivos originales en el otro extremo de la transmisión.
Tar tiene 3 modos que deberás conocer:
- Crear: hacer un archivo nuevo de una serie de archivos
- Extraer: sacar uno o más archivos de un archivo
- Listar: mostrar el contenido del archivo sin extraer
Recordar los modos es clave para averiguar las opciones de la línea de comandos necesarias para hacer lo que quieres. Además del modo, querrás asegurarte de que recuerdas dónde especificar el nombre del archivo, ya que podrías estar introduciendo varios nombres de archivo en una línea de comandos.
Aquí, mostramos un archivo tar, también llamado un tarball, siendo creado a partir de múltiples registros de acceso.
bob:tmp $ tar -cf access_logs.tar access_log* bob:tmp $ ls -l access_logs.tar -rw-rw-r-- 1 sean sean 542720 Oct 12 21:42 access_logs.tar
La creación de un archivo requiere dos opciones de nombre. La primera, c, especifica el modo. La segunda, f, le dice a tar que espere un nombre de archivo como el siguiente argumento. El primer argumento en el ejemplo anterior crea un archivo llamado access_logs.tar. El resto de los argumentos se toman para ser nombres de los archivo de entrada, ya sea un comodín, una lista de archivos o ambos. En este ejemplo, utilizamos la opción comodín para incluir todos los archivos que comienzan con access_log.
El ejemplo anterior hace un listado largo de directorio del archivo creado. El tamaño final es 542,720 bytes que es ligeramente más grande que los archivos de entrada. Los tarballs pueden ser comprimidos para transporte más fácil, ya sea comprimiendo un archivo con gzip o diciéndole a tar que lo haga con la a opción z tal como se muestra a continuación:
bob:tmp $ tar -czf access_logs.tar.gz access_log*
bob:tmp $ ls -l access_logs.tar.gz
-rw-rw-r-- 1 sean sean 46229 Oct 12 21:50 access_logs.tar.gz
bob:tmp $ gzip -l access_logs.tar.gz
compressed uncompressed ratio uncompressed_name
46229 542720 91.5% access_logs.tar
El ejemplo anterior muestra el mismo comando como en el ejemplo anterior, pero con la adición del parámetro z. La salida es mucho menor que el tarball en sí mismo, y el archivo resultante es compatible con gzip. Se puede ver en el último comando que el archivo descomprimido es del mismo tamaño, como si hubieras utilizado el tar en un paso separado.
Mientras que UNIX no trata las extensiones de archivo especialmente, la convención es usar .tar para los archivos tar y .tar.gz o .tgz para los archivos tar comprimidos. Puedes utilizar bzip2 en vez de gzip sustituyendo la letra z con j y usando .tar.bz2,.tbz, o .tbz2 para una extensión de archivo (por ejemplo tar –cjf file.tbz access_log*).
En el archivo tar, comprimido o no, puedes ver lo que hay dentro utilizando el comando t:
bob:tmp $ tar -tjf access_logs.tbz logs/ logs/access_log.3 logs/access_log.1 logs/access_log.4 logs/access_log logs/access_log.2
Este ejemplo utiliza 3 opciones:
t: listar documentos en el archivo en el archivo empaquetadoj: descomprimir conbzip2antes de la lecturaf: operar en el nombre de archivoaccess_logs.tbz
El contenido del archivo comprimido entonces es desplegado. Puedes ver que un directorio fue prefijado a los archivos. Tar se efectuará de manera recursiva hacia los subdirectorios automáticamente cuando comprime y almacenará la información de la ruta de acceso dentro del archivo.
Sólo para mostrar que este archivo aún no es nada especial, vamos a listar el contenido del archivo en dos pasos mediante una barra vertical.
bob:tmp $ bunzip2 -c access_logs.tbz | tar -t logs/ logs/access_log.3 logs/access_log.1 logs/access_log.4 logs/access_log logs/access_log.2
A la izquierda de la barra vertical está bunzip –c access_logs.tbz, que descomprime el archivo, pero el c envía la salida a la pantalla. La salida es redirigida a tar -t. Si no especificas que un archivo con –f, entonces el tar leerá la entrada estándar, que en este caso es el archivo sin comprimir.
Finalmente, puedes extraer el archivo con la marca –x:
bob:tmp $ tar -xjf access_logs.tbz bob:tmp $ ls -l total 36 -rw-rw-r-- 1 sean sean 30043 Oct 14 13:27 access_logs.tbz drwxrwxr-x 2 sean sean 4096 Oct 14 13:26 logs bob:tmp $ ls -l logs total 536 -rw-r--r-- 1 sean sean 372063 Oct 11 21:24 access_log -rw-r--r-- 1 sean sean 362 Oct 12 21:41 access_log.1 -rw-r--r-- 1 sean sean 153813 Oct 12 21:41 access_log.2 -rw-r--r-- 1 sean sean 1136 Oct 12 21:41 access_log.3 -rw-r--r-- 1 sean sean 784 Oct 12 21:41 access_log.4
El ejemplo anterior utiliza un patrón similar como antes, especificando la operación (eXtract), compresión ( (la opción j, que significa bzip2) y un nombre de archivo -f access_logs.tbz). El archivo original está intacto y se crea el nuevo directorio logs. Los archivos están dentro del directorio.
Añade la opción –v y obtendrás una salida detallada de los archivos procesados. Esto es útil para que puedas ver lo que está sucediendo:
bob:tmp $ tar -xjvf access_logs.tbz logs/ logs/access_log.3 logs/access_log.1 logs/access_log.4 logs/access_log logs/access_log.2
Es importante mantener la opción –f al final, ya que el tar asume que lo que sigue es un nombre de archivo. En el siguiente ejemplo, las opciones f y v fueron transpuestas, llevando al tar a interpretar el comando como una operación en un archivo llamado «v» (el mensaje relevante viene en itálica).
bob:tmp $ tar -xjfv access_logs.tbz tar (child): v: Cannot open: No such file or directory tar (child): Error is not recoverable: exiting now tar: Child returned status 2 tar: Error is not recoverable: exiting now
Si sólo quieres algunos documentos del archivo empaquetado puedes agregar sus nombres al final del comando, pero por defecto deben coincidir exactamente con el nombre del archivo o puedes utilizar un patrón:
bob:tmp $ tar -xjvf access_logs.tbz logs/access_log logs/access_log
El ejemplo anterior muestra el mismo archivo que antes, pero extrayendo solamente el archivo logs/access_log. La salida del comando (ya se solicitó el modo detallado con la bandera v) muestra que sólo un archivo se ha extraído.
El tar tiene muchas más funciones, como la capacidad de utilizar los patrones al extraer los archivos, excluir ciertos archivos o mostrar los archivos extraídos en la pantalla en lugar de un disco. La documentación para el tar contiene información a profundidad.
Las Barras Verticales en la Línea de Comandos
Capítulos anteriores describen la manera de usar los comandos individuales para realizar las acciones en el sistema operativo, incluyendo cómo crear/mover/eliminar los archivos y moverse en todo el sistema. Por lo general, cuando un comando ofrece salida o genera un error, la salida se muestra en la pantalla; sin embargo, esto no tiene que ser el caso.
El carácter barra vertical | (o «pipe» en inglés) puede utilizarse para enviar la salida de un comando a otro. En lugar de que se imprima en la pantalla, la salida de un comando se convierte en una entrada para el siguiente comando. Esto puede ser una herramienta poderosa, especialmente en la búsqueda de datos específicos; la la implementación de la barra vertical (o «piping» en inglés) se utiliza a menudo para refinar los resultados de un comando inicial.
Los comandos head (o «cabeza» en español) y tail (o «cola» en español) se utilizarán en muchos ejemplos a continuación para ilustrar el uso de las barras verticales. Estos comandos se pueden utilizar para mostrar solamente algunas de las primeras o las últimas líneas de un archivo (o, cuando se utiliza con una barra vertical, la salida de un comando anterior).
Por defecto, los comandos head y tail mostrarán diez líneas. Por ejemplo, el siguiente comando muestra las diez primeras líneas del archivo /etc/sysctl.conf:
sysadmin@localhost:~$ head /etc/sysctl.conf
#
# /etc/sysctl.conf - Configuration file for setting system variables
# See /etc/sysctl.d/ for additional system variables
# See sysctl.conf (5) for information.
#
#kernel.domainname = example.com
# Uncomment the following to stop low-level messages on console
#kernel.printk = 3 4 1 3
sysadmin@localhost:~$
En el ejemplo siguiente, se mostrarán las últimas diez líneas del archivo:
sysadmin@localhost:~$ tail /etc/sysctl.conf # Do not send ICMP redirects (we are not a router) #net.ipv4.conf.all.send_redirects = 0 # # Do not accept IP source route packets (we are not a router) #net.ipv4.conf.all.accept_source_route = 0 #net.ipv6.conf.all.accept_source_route = 0 # # Log Martian Packets #net.ipv4.conf.all.log_martians = 1 # sysadmin@localhost:~$
El carácter de la barra vertical permite a los usuarios utilizar estos comandos no sólo en los archivos, sino también en la salida de otros comandos. Esto puede ser útil al listar un directorio grande, por ejemplo el directorio /etc.
Que pasaría si solo queremos ver los primeros 10 elementos del directorio /etc. A continuación se ejecuta el comando ls /etc | head
sysadmin@localhost:~$ ls /etc | head adduser.conf adjtime alternatives apparmor.d apt bash.bashrc bash_completion.d bind bindresvport.blacklist blkid.conf sysadmin@localhost:~$
La salida del comando ls se pasa al comando head por el shell en vez de ser impreso a la pantalla. El comando head toma esta salida (del ls) como «datos de entrada» y luego se imprime la salida del head a la pantalla.
En el primer ejemplo, el comando de nl se utiliza para numerar las líneas de la salida de un comando anterior:
sysadmin@localhost:~$ ls -l /etc/ppp | nl 1 total 44
2 -rw------- 1 root root 78 Aug 22 2010 chap-secrets
3 -rwxr-xr-x 1 root root 386 Apr 27 2012 ip-down
4 -rwxr-xr-x 1 root root 3262 Apr 27 2012 ip-down.ipv6to4
5 -rwxr-xr-x 1 root root 430 Apr 27 2012 ip-up
6 -rwxr-xr-x 1 root root 6517 Apr 27 2012 ip-up.ipv6to4
7 -rwxr-xr-x 1 root root 1687 Apr 27 2012 ipv6-down
8 -rwxr-xr-x 1 root root 3196 Apr 27 2012 ipv6-up
9 -rw-r--r-- 1 root root 5 Aug 22 2010 options
10 -rw------- 1 root root 77 Aug 22 2010 pap-secrets
11 drwxr-xr-x 2 root root 4096 Jun 22 2012 peers
sysadmin@localhost:~$
En el ejemplo siguiente, observa que el comando ls es ejecutado primero y su salida se envía al comando nl, enumerando todas las líneas de la salida del comando ls. A continuación, se ejecuta el comando tail, mostrando las últimas cinco líneas de la salida del comando nl:
sysadmin@localhost:~$ ls -l /etc/ppp | nl | tail -5
7 -rwxr-xr-x 1 root root 1687 Apr 27 2012 ipv6-down
8 -rwxr-xr-x 1 root root 3196 Apr 27 2012 ipv6-up
9 -rw-r--r-- 1 root root 5 Aug 22 2010 options
10 -rw------- 1 root root 77 Aug 22 2010 pap-secrets
11 drwxr-xr-x 2 root root 4096 Jun 22 2012 peers
sysadmin@localhost:~$
Compara la salida anterior con el siguiente ejemplo:
sysadmin@localhost:~$ ls -l /etc/ppp | tail -5 | nl
1 -rwxr-xr-x 1 root root 1687 Apr 27 2012 ipv6-down
2 -rwxr-xr-x 1 root root 3196 Apr 27 2012 ipv6-up
3 -rw-r--r-- 1 root root 5 Aug 22 2010 options
4 -rw------- 1 root root 77 Aug 22 2010 pap-secrets
5 drwxr-xr-x 2 root root 4096 Jun 22 2012 peers
sysadmin@localhost:~$
Observa los diferentes números de línea. ¿Por qué sucede esto?
En el segundo ejemplo, la salida del comando ls se envía primero al comando tail que «capta» sólo las últimas cinco líneas de la salida. El comando tail envía esas cinco líneas para al comando nl, que los enumera del 1 al 5.
Las barras verticales pueden ser poderosas, pero es importante considerar cómo se unen los comandos con ellas para asegurar que se muestre la salida deseada.
Redirección de E/S
La Redirección de Entrada/Salida (E/S) permite que la información pase de la línea de comandos a las diferentes secuencias.
Las Barras Verticales y le Redirección
Normalmente, cuando ejecutas un comando, se muestra la salida en la ventana de la terminal. Esta salida (también llamada un canal) se llama salida estándar, simbolizada por el término stdout. El número descriptor del archivo para este canal es 1.
El error estándar (stderr) se produce cuando se produce un error durante la ejecución de un comando; tiene un descriptor de archivo de 2. Los mensajes de error también se envían a la ventana de la terminal de forma predeterminada.
La entrada estándar, stdin, por lo general la proporcionas tú a un comando escribiendo en el teclado; número descriptor de archivo es 0. Sin embargo, mediante la redirección de la entrada estándar, los archivos pueden también ser utilizados como stdin.
STDIN
La entrada estándar STDIN es la información normalmente introducida por el usuario mediante el teclado. Cuando un comando envía un prompt al shell esperando datos, el shell proporciona al usuario la capacidad de introducir los comandos, que a su vez, se envían al comando como STDIN.
STDOUT
Salida estándar o STDOUT es la salida normal de los comandos. Cuando un comando funciona correctamente (sin errores), la salida que produce se llama STDOUT. De forma predeterminada, STDOUT se muestra en la ventana de la terminal (pantalla) donde se ejecuta el comando.
STDERR
Error estándar o STDERR son mensajes de error generados por los comandos. De forma predeterminada, STDERR se muestra en la ventana de la terminal (pantalla) donde se ejecuta el comando.
La redirección de E/S permite al usuario redirigir STDIN para que los datos provengan de un archivo y la salida de STDOUT/STDERR vaya a un archivo. La redirección se logra mediante el uso de los caracteres de la flecha: < y >.
Redirigir STDOUT
STDOUT se puede dirigir a los archivos. Para empezar, observa la salida del siguiente comando que se mostrará en la pantalla:
sysadmin@localhost:~$ echo "Line 1" Line 1 sysadmin@localhost:~$
Utilizando el carácter > , la salida puede ser redirigida a un archivo:
sysadmin@localhost:~$ echo "Line 1" > example.txt sysadmin@localhost:~$ ls Desktop Downloads Pictures Templates example.txt test Documents Music Public Videos sample.txt sysadmin@localhost:~$ cat example.txt Line 1 sysadmin@localhost:~$
Este comando no muestra ninguna salida, porque la STDOUT fue enviada al archivo example.txt en lugar de la pantalla. Puedes ver el nuevo archivo con la salida del comando ls. El archivo recién creado contiene la salida del comando echo cuando se ve el contenido del archivo con el comando cat.
Es importante tener en cuenta que la flecha sola sobrescribe cualquier contenido de un archivo existente.
También es posible preservar el contenido de un archivo existente anexando al mismo. Utiliza la «doble flecha» >> para anexar a un archivo en vez de sobreescribirlo:
sysadmin@localhost:~$ cat example.txt New line 1 sysadmin@localhost:~$ echo "Another line" >> example.txt sysadmin@localhost:~$ cat example.txt New line 1 Another line sysadmin@localhost:~$
En lugar de ser sobrescrito, la salida del comando del comando echo reciente se anexa a la parte inferior del archivo.
Redirigir la STDERR
Puedes redirigir el STDERR de una manera similar a la STDOUT. STDOUT es también conocida como secuencia o canal («stream» o «channel» en inglés) #1. Al STDERR se asigna la secuencia #2.
Al utilizar las flechas para redirigir, se asumirá la secuencia #1 mientras no venga especificada otra secuencia. Por lo tanto, la secuencia #2 debe especificarse al redirigir el STDERR.
El STDERR de un comando puede enviarse a un archivo:
sysadmin@localhost:~$ ls /fake 2> error.txt sysadmin@localhost:~$ cat error.txt ls: cannot access /fake: No such file or directory sysadmin@localhost:~$
En el comando de arriba, 2> indica que todos los mensajes de error deben enviarse al archivo error.txt.
Redireccionando Múltiples Secuencias
Es posible dirigir la salida STDOUT y STDERR de un comando a la vez.
Las salidas STDOUT y STDERR pueden enviarse a un archivo mediante el uso de &> un conjunto de caracteres que significan «ambos 1> y 2>»:
sysadmin@localhost:~$ ls /fake /etc/ppp &> all.txt sysadmin@localhost:~$ cat all.txt ls: cannot access /fake: No such file or directory /etc/ppp: chap-secrets ip-down ip-down.ipv6to4 ip-up ip-up.ipv6to4 ipv6-down ipv6-up options pap-secrets peers sysadmin@localhost:~$
Ten en cuenta que cuando se utiliza &>, la salida aparece en el archivo con todos los mensajes STDERR en la parte superior y todos los mensaje STDOUT debajo de todos los mensajes de STDERR.
Si no quieres que las salidas STDERR y STDOUT vayan al mismo archivo, puede redirigirlas a diferentes archivos utilizando > and 2>. Por ejemplo:
sysadmin@localhost:~$ rm error.txt example.txt sysadmin@localhost:~$ ls Desktop Downloads Pictures Templates all.txt Documents Music Public Videos sysadmin@localhost:~$ ls /fake /etc/ppp > example.txt 2> error.txt sysadmin@localhost:~$ ls Desktop Downloads Pictures Templates all.txt example.txt Documents Music Public Videos error.txt sysadmin@localhost:~$ cat error.txt ls: cannot access /fake: No such file or directory sysadmin@localhost:~$ cat example.txt /etc/ppp: chap-secrets ip-down ip-down.ipv6to4 ip-up ip-up.ipv6to4 ipv6-down ipv6-up options pap-secrets peers sysadmin@localhost:~$
No importa el orden en el vienen las secuencias especificadas.
Buscar Archivos Utilizando el Comando Find
El comando find es una herramienta muy poderosa que puedes utilizar para buscar archivos en el sistema de archivos. Este comando puede buscar archivos por nombre, incluso usando los caracteres comodín cuando no estás seguro del nombre exacto del archivo. Además, puedes buscar los archivos en función de los metadatos de archivos, tales como tipo de archivo, tamaño de archivo y propiedad de archivo.
La sintaxis del comando find es:
find [directorio de inicio] [opción de búsqueda] [criterio de búsqueda] [opción de resultado]
Descripción de todos estos componentes:
| Component | Description |
|---|---|
| [directorio de inicio] | Aquí el usuario especifica dónde comenzar la búsqueda. El comando find buscará en este directorio y todos sus subdirectorios. Si no hay directorio de partida, el directorio actual se utiliza para el punto de partida |
| [opción de búsqueda] | Aquí el usuario especifica una opción para determinar qué tipo de metadatos hay que buscar; hay opciones para el nombre de archivo, tamaño de archivo y muchos otros atributos de archivo. |
| [criterio de búsqueda] | Es un argumento que complementa la opción de búsqueda. Por ejemplo, si el usuario utiliza la opción para buscar un nombre de archivo, el criterio de búsqueda sería el nombre del archivo. |
| [opción de resultado] | Esta opción se utiliza para especificar qué acción se debe tomar al encontrar el archivo. Si no se proporciona ninguna opción, se imprimirá el nombre del archivo a STDOUT. |
Buscar por Nombre de Archivo
Para buscar un archivo por nombre, utiliza la opción -name (o «nombre» en español) del comando find (o «buscar» en español):
sysadmin@localhost:~$ find /etc -name hosts find: `/etc/dhcp': Permission denied find: `/etc/cups/ssl': Permission denied find: `/etc/pki/CA/private': Permission denied find: `/etc/pki/rsyslog': Permission denied find: `/etc/audisp': Permission denied find: `/etc/named': Permission denied find: `/etc/lvm/cache': Permission denied find: `/etc/lvm/backup': Permission denied find: `/etc/lvm/archive': Permission denied /etc/hosts find: `/etc/ntp/crypto': Permission denied find: `/etc/polkit-l/localauthority': Permission denied find: `/etc/sudoers.d': Permission denied find: `/etc/sssd': Permission denied /etc/avahi/hosts find: `/etc/selinux/targeted/modules/active': Permission denied find: `/etc/audit': Permission denied sysadmin@localhost:~$
Observa que se encontraron dos archivos: /etc/hosts y /etc/avahi/hosts. El resto de la salida eran los mensajes STDERR porque el usuario que ejecutó el comando no tiene permiso para acceder a ciertos subdirectorios.
Recuerda que puedes redirigir el STDERR a un archivo por lo que no necesitarás ver estos mensajes de error en la pantalla:
sysadmin@localhost:~$ find /etc -name hosts 2> errors.txt /etc/hosts /etc/avahi.hosts sysadmin@localhost:~$
Mientras que la salida es más fácil de leer, realmente no hay ningún propósito para almacenar los mensajes de error en el archivo error.txt. Los desarrolladores de Linux se dieron cuenta de que sería bueno tener un archivo de «basura» (o «junk» en inglés) para enviar los datos innecesarios; se descarta cualquier archivo que envíes al archivo /dev/null:
sysadmin@localhost:~$ find /etc -name hosts 2> /dev/null /etc/hosts /etc/avahi/hosts sysadmin@localhost:~$
Mostrando los Detalles del Archivo
Puede ser útil obtener información sobre el archivo al utilizar el comando find, porque solo el nombre del archivo en sí mismo podría no proporcionar información suficiente para que puedas encontrar el archivo correcto.
Por ejemplo, puede haber siete archivos llamados hosts; si supieras que el archivo host que necesitas se había modificado recientemente, entonces sería útil ver la hora de modificación del archivo.
Para ver estos detalles del archivo, utiliza la opción -ls para el comando find:
sysadmin@localhost:~$ find /etc -name hosts -ls 2> /dev/null
41 4 -rw-r--r-- 1 root root 158 Jan 12 2010 /etc/hosts
6549 4 -rw-r--r-- 1 root root 1130 Jul 19 2011 /etc/avahi/hosts
sysadmin@localhost:~$
Nota: Las dos primeras columnas de la salida anterior son el número inodo del archivo y el número de bloques que el archivo utiliza para el almacenamiento. Ambos están más allá del alcance del tema en cuestión. El resto de las columnas son la salida típica del comando ls -l: tipo de archivo, permisos, cuenta de enlaces físico, usuario propietario, grupo propietario, tamaño del archivo, hora de modificación del archivo y el nombre de archivo.
Buscar Archivos por Tamaño
Una de las muchas opciones útiles de la búsqueda es la opción que le permite buscar archivos por tamaño. La opción -size (o «tamaño» en español) te permite buscar los archivos que son mayores o menores que un tamaño especificado, así como buscar un tamaño de archivo exacto.
Cuando se especifica un tamaño de archivo, puedes proporcionar el tamaño en bytes (c), kilobytes (k), megabytes (M) o gigabytes (G). Por ejemplo, la siguiente será una búsqueda de archivos en la estructura de directorios /etc con el tamaño exacto de 10 bytes:
sysadmin@localhost:~$ find /etc -size 10c -ls 2>/dev/null 432 4 -rw-r--r-- 1 root root 10 Jan 28 2015 /etc/adjtime 8814 0 drwxr-xr-x 1 root root 10 Jan 29 2015 /etc/ppp/ip-d own.d 8816 0 drwxr-xr-x 1 root root 10 Jan 29 2015 /etc/ppp/ip-u p.d 8921 0 lrwxrwxrwx 1 root root 10 Jan 29 2015 /etc/ssl/cert s/349f2832.0 -> EC-ACC.pem 9234 0 lrwxrwxrwx 1 root root 10 Jan 29 2015 /etc/ssl/cert s/aeb67534.0 -> EC-ACC.pem 73468 4 -rw-r--r-- 1 root root 10 Nov 16 20:42 /etc/hostname sysadmin@localhost:~$
Si quieres buscar los archivos que son más grandes que un tamaño especificado, puedes usar el carácter + antes que el tamaño. Por ejemplo, el siguiente ejemplo buscará todos los archivos en la estructura de directorio /usr que su tamaño sea mayor a 100 megabytes:
sysadmin@localhost:~$ find /usr -size +100M -ls 2> /dev/null 574683 104652 -rw-r--r-- 1 root root 107158256 Aug 7 11:06 /usr/share/icons/oxygen/icon-theme.cache sysadmin@localhost:~$
Si quieres buscar los archivos que son más pequeños que un tamaño especificado, puedes usar el carácter - antes que el tamaño.
Opciones de Búsqueda Útiles Adicionales
Hay muchas opciones de búsqueda. La siguiente tabla muestra algunas:
| Opción | Significado |
|---|---|
-maxdepth | Permite al usuario especificar la profundidad en la estructura de los directorios a buscar. Por ejemplo, -maxdepth 1 significaría sólo buscar en el directorio especificado y en sus subdirectorios inmediatos. |
-group | Devuelve los archivos que son propiedad de un grupo especificado. Por ejemplo, -group payrolldevolvería los archivos que son propiedad del grupo payroll (o «nómina» en español). |
-iname | Devuelve los archivos especificados que coinciden con el nombre de archivo, pero a diferencia del -name, -iname no es sensible a las mayúsculas y minúsculas. Por ejemplo, -iname hosts coincidiría con los archivos llamados hosts, Hosts, HOSTS, etc. |
-mmin | Devuelve los archivos que fueron modificados según el tiempo de modificación en minutos. Por ejemplo, -mmin 10 coincidirá con los archivos que fueron modificados hace 10 minutos. |
-type | Devuelve los archivos que coinciden con el tipo de archivo. Por ejemplo, -type f devuelve los archivos que son archivos regulares. |
-user | Devuelve los archivos que son propiedad de un usuario especificado. Por ejemplo, -user bob devuelve los archivos que son propiedad del usuario bob. |
Usar Múltiples Opciones
Si utilizas múltiples opciones, éstas actúan como un operador lógico «y», lo que significa que para que se dé una coincidencia, todos los criterios deben coincidir, no sólo uno. Por ejemplo, el siguiente comando muestra todos los archivos en la estructura de directorio /etc con el tamaño de 10 bytes y que son archivos simples:
sysadmin@localhost:~$ find /etc -size 10c -type f -ls 2>/dev/null 432 4 -rw-r--r-- 1 root root 10 Jan 28 2015 /etc/adjtime 73468 4 -rw-r--r-- 1 root root 10 Nov 16 20:42 /etc/hostname sysadmin@localhost:~$
Para archivos más grandes, querrás usar el comando pager que permite ver el contenido. Los comandos pager mostrarán una página de datos a la vez, permiténdote moverte hacia adelante y hacia atrás en el archivo utilizando las teclas de movimiento.
Hay dos comandos pager comúnmente utilizados:
- El comando
less: Este comando proporciona una capacidad de paginación muy avanzada. Normalmente es el pager predeterminado utilizado por comandos como el comandoman. - El comando
more: Este comando ha existido desde los primeros días de UNIX. Aunque tenga menos funciones que el comandoless, tiene una ventaja importante: El comandolessno viene siempre incluido en todas las distribuciones de Linux (y en algunas distribuciones, no viene instalado por defecto). El comandomoresiempre está disponible.
Cuando utilizas los comandos more o less, te permiten «moverte» en un documento utilizando los comandos de tecla.
Los Comandos de Movimiento para less
Hay muchos comandos de movimiento para el comando less, cada uno con múltiples teclas o combinaciones de teclas. Si bien esto puede parecer intimidante, recuerda que no necesitas memorizar todos estos comandos de movimiento; siempre puedes utilizar la tecla h para obtener la ayuda.
El primer grupo de comandos de movimiento en los que probablemente te quieras enfocar son los que más comúnmente se utilizan. Para hacerlo aún más fácil de aprender, se resumirán las teclas que son idénticas para more y less. De esta manera, aprenderás cómo moverte en los comandos more y less al mismo tiempo:
| Movimiento | Tecla |
|---|---|
| Ventana hacia adelante | Barra espaciadora |
| Ventana hacia atrás | b |
| Línea hacia adelante | Entrar |
| Salir | q |
| Ayuda | h |
Cuando se utiliza el comando less para moverse entre las páginas, la forma más fácil de avanzar una página hacia adelante es presionando la barra espaciadora.
Revisando los Comandos head y tail
Recordemos que los comandos head y tail se utilizan para filtrar los archivos y mostrar un número limitado de líneas. Si quieres ver un número de líneas seleccionadas desde la parte superior del archivo, utiliza el comando head y si quieres ver un número de líneas seleccionadas en la parte inferior de un archivo, utiliza el comando tail.
Por defecto, ambos comandos muestran diez líneas del archivo. La siguiente tabla proporciona algunos ejemplos:
| Comando de Ejemplo | Explicación del texto visualizado |
|---|---|
head /etc/passwd | Las primeras diez líneas del archivo /etc/passwd |
head -3 /etc/group | Las primeras tres líneas del archivo/etc/group |
head -n 3 /etc/group | Las primeras tres líneas del archivo /etc/group |
help | head | Las primeras diez líneas de la salida del comando help redirigidas por la barra vertical |
tail /etc/group | Las últimas diez líneas del archivo /etc/group |
tail -5 /etc/passwd | Las últimas cinco líneas del archivo /etc/passwd |
tail -n 5 /etc/passwd | Las últimas cinco líneas del archivo /etc/passwd |
help | tail | Las últimas diez líneas de la salida del comando help redirigidas por la barra vertical |
Como puedes observar en los ejemplos anteriores, ambos comandos darán salida al texto de un archivo regular o de la salida de cualquier comando enviado mediante la barra vertical. Ambos utilizan la opción -n para indicar cuántas líneas debe contener la salida.
El Valor Negativo de la Opción -n
Tradicionalmente en UNIX, se especifica el número de líneas a mostrar como una opción con cualquiera de los comandos, así pues -3 significa mostrar tres líneas. Para el comando tail, la opción -3 o -n -3 siempre significará mostrar tres líneas. Sin embargo, la versión GNU del comando head reconoce -n -3 como mostrar todo menos las tres últimas líneas, y sin embargo el comando head siempre reconoce la opción -3 como muestra las tres primeras líneas.
El Valor Positivo del Comando tail
La versión GNU del comando tail permite una variación de cómo especificar el número de líneas que se deben imprimir. Si utilizas la opción -n con un número precedido por el signo más, entonces el comando tail reconoce esto en el sentido de mostrar el contenido a partir de la línea especificada y continuar hasta el final.
Por ejemplo, el siguiente ejemplo muestra la línea #22 hasta el final de la salida del comando nl:
sysadmin@localhost:~$ nl /etc/passwd | tail -n +22
22 sshd:x:103:65534::/var/run/sshd:/usr/sbin/nologin
23 operator:x:1000:37::/root:/bin/sh
24 sysadmin:x:1001:1001:System Administrator,,,,:/home/sysadmin:/bin/bash
sysadmin@localhost:~$
Seguimiento de los Cambios en un Archivo
Puedes ver los cambios en vivo en los archivos mediante la opción -f del comando tail. Esto es útil cuando quieres seguir cambios en un archivo mientras están sucediendo.
Un buen ejemplo de esto sería cuando quieres ver los archivos de registro como el administrador de sistemas. Los archivos de registro pueden utilizarse para solucionar los problemas y a menudo los administradores los verán en una ventana independiente de manera «interactiva» utilizando el comando tail mientras van ejecutando los comandos con los cuáles están intentando solucionar los problemas.
Por ejemplo, si vas a iniciar una sesión como el usuario root, puedes solucionar los problemas con el servidor de correo electrónico mediante la visualización de los cambios en tiempo real de su archivo de registro utilizando el comando siguiente: tail -f /var/log/mail.log
Ordenar Archivos o Entradas
Puede utilizarse el comando sort para reorganizar las líneas de archivos o entradas en orden alfabético o numérico basado en el contenido de uno o más campos. Los campos están determinados por un separador de campos contenido en cada línea, que por defecto son espacios en blanco (espacios y tabuladores).
En el ejemplo siguiente se crea un pequeño archivo, usando el comando head tomando las 5 primeras líneas del archivo /etc/passwd y enviando la salida a un archivo llamado mypasswd.
sysadmin@localhost:~$ head -5 /etc/passwd > mypasswd sysadmin@localhost:~$
sysadmin@localhost:~$ cat mypasswd root:x:0:0:root:/root:/bin/bash daemon:x:1:1:daemon:/usr/sbin:/bin/sh bin:x:2:2:bin:/bin:/bin/sh sys:x:3:3:sys:/dev:/bin/sh sync:x:4:65534:sync:/bin:/bin/sync sysadmin@localhost:~$
Ahora vamos a ordenar (sort) el archivo mypasswd:
sysadmin@localhost:~$ sort mypasswd bin:x:2:2:bin:/bin:/bin/sh daemon:x:1:1:daemon:/usr/sbin:/bin/sh root:x:0:0:root:/root:/bin/bash sync:x:4:65534:sync:/bin:/bin/sync sys:x:3:3:sys:/dev:/bin/sh sysadmin@localhost:~$
Opciones de Campo y Ordenamiento
En el caso de que el archivo o entrada pueda separarse por otro delimitador como una coma o dos puntos, la opción -t permitirá especificar otro separador de campo. Para especificar los campos para sort (o en español «ordenar»), utiliza la opción -k con un argumento para indicar el número de campo (comenzando con 1 para el primer campo).
Las otras opciones comúnmente usadas para el comando sort son -n para realizar un sort numérico y -r para realizar a un sort inverso.
En el siguiente ejemplo, se utiliza la opción -t para separar los campos por un carácter de dos puntos y realiza un sort numérico utilizando el tercer campo de cada línea:
sysadmin@localhost:~$ sort -t: -n -k3 mypasswd root:x:0:0:root:/root:/bin/bash daemon:x:1:1:daemon:/usr/sbin:/bin/sh bin:x:2:2:bin:/bin:/bin/sh sys:x:3:3:sys:/dev:/bin/sh sync:x:4:65534:sync:/bin:/bin/sync sysadmin@localhost:~$
Ten en cuenta que la opción -r se podía haber utilizado para invertir el sort, causando que los números más altos en el tercer campo aparecieran en la parte superior de la salida:
sysadmin@localhost:~$ sort -t: -n -r -k3 mypasswd sync:x:4:65534:sync:/bin:/bin/sync sys:x:3:3:sys:/dev:/bin/sh bin:x:2:2:bin:/bin:/bin/sh daemon:x:1:1:daemon:/usr/sbin:/bin/sh root:x:0:0:root:/root:/bin/bash sysadmin@localhost:~$
Por último, puede que quieras ordenarlo de una forma más compleja, como un sort por un campo primario y luego por un campo secundario. Por ejemplo, considera los siguientes datos:
bob:smith:23 nick:jones:56 sue:smith:67
Puede que quieras ordenar primero por el apellido (campo #2), luego el nombre (campo #1) y luego por edad (campo #3). Esto se puede hacer con el siguiente comando:
sysadmin@localhost:~$ sort -t: -k2 -k1 -k3n filename
Visualización de las Estadísticas de Archivo con el Comando wc
El comando wc permite que se impriman hasta tres estadísticas por cada archivo, así como el total de estas estadísticas, siempre que se proporcione más de un nombre de archivo. De forma predeterminada, el comando wc proporciona el número de líneas, palabras y bytes (1 byte = 1 carácter en un archivo de texto):
sysadmin@localhost:~$ wc /etc/passwd /etc/passwd- 35 56 1710 /etc/passwd 34 55 1665 /etc/passwd- 69 111 3375 total sysadmin@localhost:~$
El ejemplo anterior muestra la salida de ejecutar: wc /etc/passwd /etc/passwd-. La salida tiene cuatro columnas: el número de líneas en el archivo, el número de palabras en el archivo, el número de bytes en el archivo y el nombre de archivo o total.
Si quieres ver estadísticas específicas, puede utilizar -l para mostrar sólo el número de líneas, -w para mostrar sólo el número de palabras y -c para mostrar sólo el número de bytes.
El comando wc puede ser útil para contar el número de líneas devueltas por algún otro comando utilizando la barra vertical. Por ejemplo, si desea saber el número total de los archivos en el directorio /etc, puedes ejecutar ls /etc | wc -l:
sysadmin@localhost:~$ ls /etc/ | wc -l 136 sysadmin@localhost:~$
Utilizar el Comando cut para Filtrar el Contenido del Archivo
El comando cut (o «cortar» en español) puede extraer columnas de texto de un archivo o entrada estándar. El uso primario del comando cut es para trabajar con los archivos delimitados de las bases de datos. Estos archivos son muy comunes en los sistemas Linux.
De forma predeterminada, considera que su entrada debe ser separada por el carácter Tab, pero la opción -d puede especificar delimitadores alternativos como los dos puntos o la coma.
Utilizando la opción -f puedes especificar qué campos quieres que se muestren, ya sea como un rango separado por guiones o una lista separada por comas.
En el ejemplo siguiente se visualiza el primero, quinto, sexto y séptimo campo del archivo de la base de datos de mypasswd:
sysadmin@localhost:~$ cut -d: -f1,5-7 mypasswd root:root:/root:/bin/bash daemon:daemon:/usr/sbin:/bin/sh bin:bin:/bin:/bin/sh sys:sys:/dev:/bin/sh sync:sync:/bin:/bin/sync sysadmin@localhost:~$
Con el comando cut puedes también extraer las columnas de un texto basado en la posición de los caracteres con la opción -c. Esto puede ser útil para extraer los campos de archivos de base de datos con un ancho fijo. El siguiente ejemplo muestra sólo el tipo de archivo (carácter #1), los permisos (caracteres #2-10) y el nombre de archivo (caracteres #50+) de la salida del comando ls -l:
sysadmin@localhost:~$ ls -l | cut -c1-11,50- total 12 drwxr-xr-x Desktop drwxr-xr-x Documents drwxr-xr-x Downloads drwxr-xr-x Music drwxr-xr-x Pictures drwxr-xr-x Public drwxr-xr-x Templates drwxr-xr-x Videos -rw-rw-r-- errors.txt -rw-rw-r-- mypasswd -rw-rw-r-- new.txt sysadmin@localhost:~$
Utilizar el Comando grep para Filtrar el Contenido del Archivo
Puedes utilizar el comando grep para filtrar las líneas en un archivo o en la salida de otro comando basado en la coincidencia de un patrón. El patrón puede ser tan simple como el texto exacto que quieres que coincida o puede ser mucho más avanzado mediante el uso de las expresiones regulares.
Por ejemplo, puedes querer encontrar todos los usuarios que pueden ingresar al sistema con el shell BASH, por lo que se podría utilizar el comando grep para filtrar las líneas del archivo /etc/passwd para las líneas que contengan los caracteres bash:
sysadmin@localhost:~$ grep bash /etc/passwd root:x:0:0:root:/root:/bin/bash sysadmin:x:1001:1001:System Administrator,,,,:/home/sysadmin:/bin/bash sysadmin@localhost:~$
Para que sea más fácil ver exactamente lo que coincide, utiliza la opción de --color. Esta opción resaltará los elementos coincidentes en rojo:
sysadmin@localhost:~$ grep --color bash /etc/passwd root:x:0:0:root:/root:/bin/bash sysadmin:x:1001:1001:System Administrator,,,,:/home/sysadmin:/bin/bash sysadmin@localhost:~$
En algunos casos no te interesan las líneas específicas que coinciden con el patrón, sino más bien cuántas líneas coinciden con el patrón. Con la opción -c puedes obtener un conteo del número de líneas que coinciden:
sysadmin@localhost:~$ grep -c bash /etc/passwd 2 sysadmin@localhost:~$
Cuando estás viendo la salida del comando grep, puede ser difícil determinar el número original de las líneas. Esta información puede ser útil cuando regreses al archivo (tal vez para editar el archivo), ya que puedes utilizar esta información para encontrar rápidamente una de las líneas coincidentes.
La opción -n del comando grep muestra los números de la línea originales:
sysadmin@localhost:~$ grep -n bash /etc/passwd 1:root:x:0:0:root:/root:/bin/bash 24:sysadmin:x:1001:1001:System Administrator,,,,:/home/sysadmin:/bin/bas sysadmin@localhost:~$
Algunas opciones adicionales del grep que pueden resultar útiles:
| Ejemplos | Salida |
|---|---|
grep -v nologin /etc/passwd | Todas las líneas que no contengan nologin en el archivo /etc/passwd |
grep -l linux /etc/* | Lista de los archivos en el directorio /etc que contengan linux |
grep -i linux /etc/* | Listado de las líneas de los archivos en el directorio /etc que contengan cualquier tipo de letra (mayúscula o minúscula) del patrón de caracteres linux |
grep -w linux /etc/* | Listado de las líneas de los archivos en el directorio /etc que contengan el patrón de la palabra linux |
Las Expresiones Regulares Básicas
Una Expresión Regular es una colección de caracteres «normales» y «especiales» que se utilizan para que coincida con un patrón simple o complejo. Los caracteres normales son caracteres alfanuméricos que coinciden con ellos mismos. Por ejemplo, la letra a coincide con una a.
Algunos caracteres tienen significados especiales cuando se utilizan dentro de los patrones por comandos como el comando grep. Existen las Expresiones Regulares Básicas (disponible para una amplia variedad de comandos de Linux) y las Expresiones Regulares Extendidas (disponibles para los comandos más avanzados de Linux). Las Expresiones Regulares Básicas son las siguientes:
| Expresión Regular | Coincidencias |
|---|---|
. | Cualquier carácter individual |
[ ] | Una lista o rango de caracteres que coinciden con un carácter, a menos que el primer carácter sea el símbolo de intercalación ^, lo que entonces significa cualquier carácter que no esté en la lista |
* | El carácter previo que se repite cero o más veces |
^ | El texto siguiente debe aparecer al principio de la línea |
$ | El texto anterior debe aparecer al final de la línea |
El comando grep es sólo uno de los muchos comandos que admiten expresiones regulares. Algunos otros comandos son los comandos more y less. Mientras que a algunas de las expresiones regulares se les ponen innecesariamente con comillas simples, es una buena práctica utilizar comillas simples con tus expresiones regulares para evitar que el shell trate a interpretar su significado especial.
Expresiones Regulares Básicas – el Carácter .
En el ejemplo siguiente, un simple archivo primero se crea usando la redirección. Después el comando grep se utiliza para mostrar una coincidencia de patrón simple:
sysadmin@localhost:~$ echo 'abcddd' > example.txt sysadmin@localhost:~$ cat example.txt abcddd sysadmin@localhost:~$ grep --color 'a..' example.txt abcddd sysadmin@localhost:~$
En el ejemplo anterior, se puede ver que el patrón a.. coincidió con abc. El primer carácter . coincidió con b y el segundo coincidió con c.
En el siguiente ejemplo, el patrón a..c no coincide con nada, así que el comando grep no produce ninguna salida. Para que la coincidencia tenga éxito, hay que poner dos caracteres entre a y c en el example.txt:
sysadmin@localhost:~$ grep --color 'a..c' example.txt sysadmin@localhost:~$
Expresiones Regulares Básicas – el Carácter [ ]
Si usas el carácter ., entonces cualquier carácter posible podría coincidir. En algunos casos quieres especificar exactamente los caracteres que quieres que coincidan. Por ejemplo, tal vez quieres que coincida un sólo carácter alfa minúscula o un carácter de número. Para ello, puedes utilizar los caracteres de expresiones regulares [ ] y especificar los caracteres válidos dentro de los caracteres [ ].
Por ejemplo, el siguiente comando coincide con dos caracteres, el primero es ya sea una a o una b mientras que el segundo es una a, b, c o d:
sysadmin@localhost:~$ grep --color '[ab][a-d]' example.txt abcddd sysadmin@localhost:~$
Ten en cuenta que puedes enumerar cada carácter posible [abcd] o proporcionar un rango [a-d] siempre que esté en el orden correcto. Por ejemplo, [d-a] no funcionaría ya que no es un intervalo válido:
sysadmin@localhost:~$ grep --color '[d-a]' example.txt grep: Invalid range end sysadmin@localhost:~$
El rango se especifica mediante un estándar denominado la tabla ASCII. Esta tabla es una colección de todos los caracteres imprimibles en un orden específico. Puedes ver la tabla ASCII con el comando man ascii. Un pequeño ejemplo:
041 33 21 ! 141 97 61 a
042 34 22 “ 142 98 62 b
043 35 23 # 143 99 63 c
044 36 24 $ 144 100 64 d
045 37 25 % 145 101 65 e
046 38 26 & 146 102 66 f
Puesto que la a tiene un valor numérico más pequeño (141) que la d (144), el rango a-d incluye todos los caracteres de la a a la d.
¿Qué pasa si quieres un carácter que puede ser cualquier cosa menos una x, y o z? No querrías proporcionar un conjunto de [ ] con todos los caracteres excepto x, y o z.
Para indicar que quieres que coincida un carácter que no es uno de lo listados, inicia tu conjunto de [ ] con el símbolo ^. El siguiente ejemplo muestra la coincidencia de un patrón que incluye un carácter que no es un a, b o c seguida de un d:
sysadmin@localhost:~$ grep --color '[^abc]d' example.txt abcddd sysadmin@localhost:~$
Expresiones Regulares Básicas – el Carácter *
El carácter * se puede utilizar para coincidir con «cero o más de los caracteres previos». El siguiente ejemplo coincidirá con cero o más caracteres d:
sysadmin@localhost:~$ grep --color 'd*' example.txt abcddd sysadmin@localhost:~$
Expresiones Regulares Básicas – los Caracteres ^ y $
Cuando quieres que coincida un patrón, tal coincidencia puede ocurrir en cualquier lugar de la línea. Puede que quieras especificar que la coincidencia se presentara al principio de la línea o al final de la línea. Para que coincida con el principio de la línea, comienza el patrón con el símbolo ^.
En el ejemplo siguiente se agrega otra línea al archivo example.txt para mostrar el uso del símbolo ^:
sysadmin@localhost:~$ echo "xyzabc" >> example.txt sysadmin@localhost:~$ cat example.txt abcddd xyzabc sysadmin@localhost:~$ grep --color "a" example.txt abcddd xyzabc sysadmin@localhost:~$ grep --color "^a" example.txt abcddd sysadmin@localhost:~$
Ten en cuenta que en la primera salida del grep, ambas líneas coinciden debido a que ambas contienen la letra a. En la segunda salida grep, solo coincide con la línea que comienza con la letra a.
Para especificar que coincida al final de la línea, termina el patrón con el carácter $. Por ejemplo, para encontrar sólo las líneas que terminan con la letra c:
sysadmin@localhost:~$ grep "c$" example.txt xyzabc sysadmin@localhost:~$
Expresiones Regulares Básicas – el Carácter \
En algunos casos querrás que la búsqueda coincida con un carácter que resulta ser un carácter especial de la expresión regular. Observa el siguiente ejemplo:
sysadmin@localhost:~$ echo "abcd*" >> example.txt sysadmin@localhost:~$ cat example.txt abcddd xyzabc abcd* sysadmin@localhost:~$ grep --color "cd*" example.txt abcddd xyzabc abcd* sysadmin@localhost:~$
En la salida del comando grep anterior, ves que cada línea corresponde porque estás buscando el carácter c seguido de cero o más caracteres d. Si quieres buscar un carácter *, coloca el carácter \ antes del carácter *:
sysadmin@localhost:~$ grep --color "cd\*" example.txt abcd* sysadmin@localhost:~$
Expresiones Regulares Extendidas
El uso de las Expresiones Regulares Extendidas requiere a menudo una opción especial proporcionada al comando para que éste las reconozca. Históricamente, existe un comando llamado egrep, que es similar al grep, pero es capaz de entender su uso. Ahora, el comando egrep es obsoleto a favor del uso del grep con la opción -E.
Las siguientes expresiones regulares se consideran «extendidas»:
| RE | Significado |
|---|---|
? | Coincide con el carácter anterior cero o una vez más, así que es un carácter opcional |
+ | Coincide con el carácter anterior repetido una o más veces |
| | Alternación o como un operador lógico |
Algunos ejemplos de expresiones regulares extendidas:
| Comando | Significado | Coincidencias |
|---|---|---|
grep -E 'colou?r' 2.txt | Haz coincidir colo seguido por cero o un carácter u | color colour |
grep -E 'd+' 2.txt | Coincide con uno o más d caracteres | d dd ddd dddd |
grep -E 'gray|grey' 2.txt | Coincide con gray o grey | gray grey |
El Command xargs
El comando xargs se utiliza para construir y ejecutar líneas de comandos de una entrada estándar. Este comando es muy útil cuando se necesita ejecutar un comando con una lista de argumentos muy larga, que en algunos casos puede resultar en un error si la lista de argumentos es demasiado larga.
El comando xargs tiene una opción -0, que desactiva la cadena de fin de archivo, permitiendo el uso de los argumentos que contengan espacios, comillas o barras diagonales inversas.
El comando xargs es útil para permitir que los comandos se ejecuten de manera más eficiente. Su objetivo es construir la línea de comandos para que un comando se ejecute las menos veces posibles con tantos argumentos como sea posible, en lugar de ejecutar el comando muchas veces con un argumento cada vez.
El comando xargs funciona separando la lista de los argumentos en sublistas y ejecutando el comando con cada sublista. El número de los argumentos en cada sublista no excederá el número máximo de los argumentos para el comando ejecutado, y por lo tanto, evita el error de «Argument list too long» (o «Lista de argumentos demasiado larga» en español).
En el ejemplo siguiente se muestra un escenario donde el comando xargs permite que muchos archivos sean eliminados, y donde el uso de un carácter comodín normal (glob) falló:
sysadmin@localhost:~/many$ rm * bash: /bin/rm: Argument list too long sysadmin@localhost:~/many$ ls | xargs rm sysadmin@localhost:~/many$
Scripts Shell en Pocas Palabras
Un script shell es un archivo de comandos ejecutables que ha sido almacenado en un archivo de texto. Cuando el archivo se ejecuta, se ejecuta cada comando. Los scripts shell tienen acceso a todos los comandos del shell, incluyendo la lógica. Un script (o «secuencia de comandos» en español), por lo tanto, puede detectar la presencia de un archivo o buscar una salida particular y cambiar su comportamiento en consecuencia. Se pueden crear scripts para automatizar partes repetitivas de tu trabajo, que ahorran tu tiempo y aseguran consistencia cada vez que utilices el script. Por ejemplo, si ejecutas los mismos cinco comandos todos los días, puedes convertirlos en un script shell que reduce tu trabajo a un comando.
Un script puede ser tan simple como un único comando:
echo “Hello, World!”
El script, test.sh, consta de una sola línea que imprime la cadena Hello, World! (o «¡Hola, Mundo!» en español) en la consola.
Ejectutar un script puede hacerse, ya sea pasándolo como un argumento a tu shell o ejecuándolo directamente:
sysadmin@localhost:~$ sh test.sh Hello, World! sysadmin@localhost:~$ ./test.sh -bash: ./test.sh: Permission denied sysadmin@localhost:~$ chmod +x ./test.sh sysadmin@localhost:~$ ./test.sh Hello, World!
En el ejemplo anterior, en primer lugar, el script se ejecuta como un argumento del shell. A continuación, se ejecuta el script directamente desde el shell. Es raro tener el directorio actual en la ruta de búsqueda binaria $PATH, por lo que el nombre viene con el prefijo ./ para indicar que se debe ejecutar en el directorio actual.
El error Permission denied (o «Permiso denegado» en español) significa que el script no ha sido marcado como ejecutable. Un comando chmod rápido después y el script funciona. El comando chmod se utiliza para cambiar los permisos de un archivo, que se explica en detalle en un capítulo posterior.
Hay varios shells con su propia sintaxis de lenguaje. Por lo tanto, los scripts más complicados indicarán un shell determinado, especificando la ruta absoluta al intérprete como la primera línea, con el prefijo #!, tal como lo muestra el siguiente ejemplo:
#!/bin/sh echo “Hello, World!”
o
#!/bin/bash echo “Hello, World!”
Los dos caracteres #! se llaman tradicionalmente el hash y el bang respectivamente, que conduce a la forma abreviada «shebang» cuando se utilizan al principio de un script.
Por cierto, el shebang (o crunchbang) se utiliza para los scripts shell tradicionales y otros lenguajes basados en texto como Perl, Ruby y Python. Cualquier archivo de texto marcado como ejecutable se ejecutará bajo el intérprete especificado en la primera línea mientras se ejecuta el script directamente. Si el script se invoca directamente como argumento a un intérprete, como sh script o bash script, se utilizará el shell proporcionado, independientemente de lo que está en la línea del shebang. Ayuda sentirse cómodo utilizando un editor de texto antes de escribir los scripts shell, ya que se necesitarás crear los archivos de texto simple. Las herramientas de oficina tradicionales como LibreOffice, que dan salida a archivos que contienen la información de formato y otra información, no son adecuadas para esta tarea.
Un ejemplo de un script
#!/bin/sh echo "Hello, World!" echo -n "the time is " date
Para ejecutarlo se usa sh test.sh o ./test.sh
El Scripting Básico
Anteriormente en este capítulo tuviste tu primera experiencia de scripting y recibiste una introducción a un script muy básico que ejecuta un comando simple. El script comenzó con la línea shebang, que le dice al Linux que tiene que utilizar el /bin/bash (lo que es Bash) para ejecutar un script.
Aparte de ejecutar comandos, hay 3 temas que debes conocer:
- Las variables, que contienen información temporal en el script
- Las condicionales, que te dejan hacer varias cosas basadas en las pruebas que vas introduciendo
- Los Loops, que te permiten hacer lo mismo una y otra vez
Las Variables
Las variables son una parte esencial de cualquier lenguaje de programación. A continuación se muestra un uso muy simple de las variables:
#!/bin/bash ANIMAL="penguin" echo "My favorite animal is a $ANIMAL"
Después de la línea shebang está una directiva para asignar un texto a una variable. El nombre de la variable es ANIMAL y el signo de igual asigna la cadena penguin (o «pingüino» en español). Piensa en una variable como una caja en la que puedes almacenar cosas. Después de ejecutar esta línea, la caja llamada ANIMAL contiene la palabra penguin.
Es importante que no haya ningún espacio entre el nombre de la variable, el signo de igual y el elemento que se asignará a la variable. Si le pones espacio, obtendrás un error como «command not found». No es necesario poner la variable en mayúsculas pero es una convención útil para separar las variables de los comandos que se ejecutarán.
Así que recuerda esto: Para asignar una variable, usa el nombre de la variable. Para acceder al contenido de la variable, pon el prefijo del signo de dólar. ¡A continuación, vamos a mostrar una variable a la que se asigna el contenido de otra variable!
#!/bin/bash ANIMAL=penguin SOMETHING=$ANIMAL echo "My favorite animal is a $SOMETHING"
ANIMAL contiene la cadena penguin (como no hay espacios, se muestra la sintaxis alternativa sin usar las comillas). A SOMETHING se le asigna el contenido de ANIMAL (porque a la variable ANIMAL le procede el signo de dólar).
Otra forma de asignar una variable es utilizar la salida de otro comando como el contenido de la variable incluyendo el comando entre los comillas invertidas:
#!/bin/bash CURRENT_DIRECTORY=`pwd` echo "You are in $CURRENT_DIRECTORY"
Este patrón a menudo se utiliza para procesar texto. Puedes tomar el texto de una variable o un archivo de entrada y pasarlo por otro comando como sed o awk para extraer ciertas partes y guardar el resultado en una variable.
Es posible obtener entradas del usuario de su script y asignarlo a una variable mediante el comando read (o «leer» en español):
#!/bin/bash echo -n "What is your name? " read NAME echo "Hello $NAME!"
El comando read puede aceptar una cadena directo desde el teclado o como parte de la redirección de comandos tal como aprendiste en el capítulo anterior.
Hay algunas variables especiales además de las establecidas. Puedes pasar argumentos a tu script:
#!/bin/bash echo "Hello $1"
El signo de dólar seguido de un número N corresponde al argumento Nth pasado al script. Si invocas al ejemplo anterior con ./test.sh el resultado será Hola Linux. La variable $0 contiene el nombre del script.
Después de que un programa se ejecuta, ya sea un binario o un script, devuelve el exit code (o «código de salida» en español) que es un número entero entre 0 y 255. Puedes probarlo con la variable $? para ver si el comando anterior se ha completado con éxito.
sysadmin@localhost:~$ grep -q root /etc/passwd sysadmin@localhost:~$ echo $? 0 sysadmin@localhost:~$ grep -q slartibartfast /etc/passwd sysadmin@localhost:~$ echo $? 1
Se utilizó el comando grep para buscar una cadena dentro de un archivo con el indicador -q, que significa «silencioso» (o «quiet» en inglés). El grep, mientras se ejecuta en modo silencioso, devuelve 0, si la cadena se encontró y 1 en el caso contrario. Esta información puede utilizarse en un condicional para realizar una acción basada en la salida de otro comando.
Además puedes establecer el código de salida de tu propio script con el comando exit:
#!/bin/bash # Something bad happened! exit 1
El ejemplo anterior muestra un comentario #. Todo lo que viene después de la etiqueta hash se ignora, se puede utilizar para ayudar al programador a dejar notas. El comando exit 1 devuelve el código de salida 1 al invocador. Esto funciona incluso en el shell. Si ejecutas este script desde la línea de comandos y luego introduces echo $?, verás que devolverá 1.
Por convención, un código de salida de 0 significa «todo está bien». Cualquier código de salida mayor que 0 significa que ocurrió algún tipo de error, que es específico para el programa. Viste que grep utiliza 1 lo que significa que la cadena no se encontró.
Condicionales
Ahora que puedes ver y definir las variables, es hora de hacer que tus propios scripts tengan diferentes funciones basadas en pruebas, llamado branching (o «ramificación» español). La instrucción if (o «si» en español) es el operador básico para implementar un branching.
La instrucción if se ve así:
if somecommand; then # do this if somecommand has an exit code of 0 fi
El siguiente ejemplo ejecutará «somecommand» (en realidad, todo hasta el punto y coma) y si el código de salida es 0, entonces se ejecutará el contenido hasta el cierre fi. Usando lo que sabes acerca del grep, ahora puedes escribir un script que hace cosas diferentes, basadas en la presencia de una cadena en el archivo de contraseñas:
#!/bin/bash if grep -q root /etc/passwd; then echo root is in the password file else echo root is missing from the password file fi
De los ejemplos anteriores podrías recordar que el código de salida del grep es 0 si se encuentra la cadena. El ejemplo anterior utiliza esto en una línea para imprimir un mensaje si root está en el archivo passwd, u otro mensaje si no es así. La diferencia aquí es que en lugar de un fi para cerrar, el bloque if, hay un else. Esto te permite realizar una acción si la condición es verdadera, y otra si la condición es falsa. El bloque else siempre debe cerrarse con la palabra clave fi.
Otras tareas comunes son buscar la presencia de un archivo o directorio y comparar cadenas y números. Podrías iniciar un archivo de registro si no existe, o comparar el número de líneas en un archivo con la última vez que se ejecutó. El comando if es claramente de ayuda aquí, pero ¿qué comando debes usar para hacer la comparación?
El comando test te da un acceso fácil los operadores de prueba de comparación y archivos. Por ejemplo:
| Comando | Descripción |
|---|---|
test –f /dev/ttyS0 | 0 si el archivo existe |
test ! –f /dev/ttyS0 | 0 si el archivo no existe |
test –d /tmp | 0 si el directorio existe |
test –x `which ls` | sustituir la ubicación de ls y luego (probar) test, si el usuario puede ejecutar |
test 1 –eq 1 | 0 si tiene éxito la comparación numérica |
test ! 1 –eq 1 | NO – 0 si la comparación falla |
test 1 –ne 1 | Más fácil, ejecutar test (probar) si hay desigualdad numérica |
test “a” = “a” | 0 si tiene éxito la comparación de cadenas |
test “a” != “a” | 0 si las cadenas son diferentes |
test 1 –eq 1 –o 2 –eq 2 | -o es OR: cualquiera de las opciones pueden ser igual |
test 1 –eq 1 –a 2 –eq 2 | -a es AND: ambas comparaciones deben ser iguales |
Es importante tener en cuenta que el test ve las comparaciones de números enteros y cadenas de manera distinta. 01 y 1 son iguales por comparación numérica, pero no para comparación de cadenas o strings. Siempre debes tener cuidado y recordar qué tipo de entrada esperas.
Hay muchas más pruebas, como –gt para mayor que, formas de comprobar si un archivo es más reciente que los otros y muchos más. Para más información consulta la página test man.
La salida de test es bastante largo para un comando que se usa con tanta frecuencia, por lo que tiene un alias llamado [ (corchete cuadrado izquierdo). Si incluyes tus condiciones en corchetes, es lo mismo que si ejecutaras el test. Por lo tanto, estas instrucciones son idénticas.
if test –f /tmp/foo; then if [ -f /tmp/foo]; then
Mientras que la última forma es de uso más frecuente, es importante entender que el corchete es un comando en sí que funciona de manera semejante al test excepto que requiere el corchete cuadrado de cierre.
La instrucción if tiene una forma final que te permite hacer varias comparaciones al mismo tiempo usando elif (abreviatura de elseif).
#!/bin/bash if [ "$1" = "hello" ]; then echo "hello yourself" elif [ "$1" = "goodbye" ]; then echo "nice to have met you" echo "I hope to see you again" else echo "I didn't understand that" fi
El código anterior compara el primer argumento pasado al script. Si es hello, se ejecuta el primer bloque. Si no es así, el script de comandos comprueba si es goodbye e invoca con el comando echo con un diferente mensaje entonces. De lo contrario, se envía un tercer mensaje. Ten en cuenta que la variable $1 viene entre comillas y se utiliza el operador de comparación de cadenas en lugar de la versión numérica (-eq).
Las pruebas if/elif/else pueden ser bastante detalladas y complicadas. La instrucción case proporciona una forma distinta de hacer las pruebas múltiples más fáciles.
#!/bin/bash case "$1" in hello|hi) echo "hello yourself" ;; goodbye) echo "nice to have met you" echo "I hope to see you again" ;; *) echo "I didn't understand that" esac
La instrucción case comienza con la descripción de la expresión que se analiza: case EXPRESSION in. La expresión aquí es $1 entre comillas.
A continuación, cada conjunto de pruebas se ejecutan como una coincidencia de patrón terminada por un paréntesis de cierre. El ejemplo anterior primero busca hello o hi; múltiples opciones son separadas por la barra vertical | que es un operador OR en muchos lenguajes de programación. Después de esto, se ejecutan los comandos si el patrón devuelve verdadero y se terminan con dos signos de punto y coma. El patrón se repite.
El patrón * es igual a else, ya que coincide con cualquier cosa. El comportamiento de la instrucción case es similar a la instrucción if/elif/else en que el proceso se detiene tras la primera coincidencia. Si ninguna de las otras opciones coincide, el patrón * asegurá que coincida con la última.
Con una sólida comprensión de las condicionales puedes hacer que tus scripts tomen acción sólo si es necesario.
Los Loops
Los loops (o «ciclos o bucles» en español) permiten que un código se ejecute repetidas veces. Pueden ser útiles en numerosas situaciones, como cuando quieres ejecutar los mismos comandos sobre cada archivo en un directorio, o repetir alguna acción 100 veces. Hay dos loops principales en los scripts del shell: el loop for y el loop while.
Los loops for se utilizan cuando tienes una colección finita que quieres repetir, como una lista de archivos o una lista de nombres de servidor:
#!/bin/bash SERVERS="servera serverb serverc" for S in $SERVERS; do echo "Doing something to $S" done
Primero, el script establece una variable que contiene una lista de nombres de servidor separada por espacios. La instrucción for entonces cicla (realiza «loops») sobre la lista de los servidores, cada vez que establece la variable S con el nombre del servidor actual. La elección de la S es arbitraria, pero ten en cuenta que la S no tiene un signo de dólar, pero en el $SERVERS sí lo tiene, lo que muestra que se $SERVERS se extenderá a la lista de servidores. La lista no tiene que ser una variable. Este ejemplo muestra dos formas más para pasar una lista.
#!/bin/bash for NAME in Sean Jon Isaac David; do echo "Hello $NAME" done for S in *; do echo "Doing something to $S" done
El primer loop es funcionalmente el mismo que en el ejemplo anterior, excepto que la lista se pasa directamente al loop for en lugar de usar una variable. Usar una variable ayuda a que el script sea más claro, ya que una persona fácilmente puede realizar cambios en la variable en lugar de ver el loop.
El segundo loop utiliza comodín * que es un file glob. El shell expande eso a todos los archivos en el directorio actual.
El otro tipo de loop, un loop while, opera en una lista de tamaño desconocido. Su trabajo es seguir ejecutándose y en cada iteración realizar un test para ver si se tiene que ejecutar otra vez. Lo puedes ver como «mientras que una condición es verdadera, haz cosas».
#!/bin/bash i=0 while [ $i -lt 10 ]; do echo $i i=$(( $i + 1)) done echo "Done counting"
El ejemplo anterior muestra un loop while que cuenta de 0 a 9. Un contador de variables, i, arranca en 0. Luego, un loop while se ejecuta con un test siendo «is $i less than 10?» (o «¿es $i menor que 10?») ¡Ten en cuenta que el loop while utiliza la misma notación que la instrucción if.
Dentro del loop while el valor actual de i es mostrado en pantalla, y luego se le añade 1 a través del comando $((aritmética)) y se asigna de regreso al i. Una vez que i llega a 10, la instrucción while regresa falso y el proceso continuará después del loop.
Creditos > netacad.com