Capítulo para compartir notas sobre librerías de Python para Inteligencia Artificial.
Pandas
Importar librería
import pandas as pdDataFrame
Es como una hoja de Excel, se pueden crear manualmente o subir un archivo de Excel.
Crear DataFrame manualmente.
items = {'Raul' : [10,20,30],
'Adriana' : [40,50,60]}
df = pd.DataFrame(items)
print(df)Crear DataFrame con librería.
items = {'Raul' : pd.Series([10,20,30], ['apple', 'banana', 'mango']},
'Adriana' : pd.Series([40,50,60], ['apple', 'orange', 'mango']}
df = pd.DataFrame(items)
print(df)Conocer el índice de un DataFrame.
df.indexDevolver los valores el DataFrame.
df.valuesVer los nombres de las columnas.
df.columnsVer las dimensiones, filas y columnas respectivamente.
df.shapeObtener una sola columna del DataFrame.
df = pdDataFrame(items, columns = ['Raul'])
print(df)Ver una columna con solo los índices necesarios.
df = pdDataFrame(items, columns = ['Raul'], index = ['apple', 'banana'])
print(df)Ahora importaremos un archivo csv y empezaremos a usarlo para nuestro propósito.
Pandas utiliza varios tipos de archivos, pero los mas usados son los csv o datos separados por coma.
Poder descargar el siguiente archivo csv o ir al enlace https://www.kaggle.com/ y descargarlo, allí encontrarán muchos ejercicios donde muchas compañías suben sus problemas y las mejores soluciones son acreedoras a un premio. .
Importar Pandas
import pandas as pdCrear un DataFrame a partir de un archivo externo.
df = pd.read_csv('data_fifa.csv')Ver las 5 primeras filas en un DataFrame.
df.head()Ver mas de 5 filas.
df.head(10)Ver las 5 últimas filas en un DataFrame.
df.tail()Ver un número exacto de las últimas filas.
df.tail(3)Ver las variables estadísticas más importantes de un DataFrame.
df.describe()Ver el máximo valor de acuerdo a las columnas.
df.max()Ver el mínimo valor de acuerdo a las columnas.
df.min()Ver la correlación para saber como las columnas están relacionadas.
df.corr()Ver cuantos jugadores están en el Club FC Barcelona.
Club es una Columna.
df[df['Club'] == 'FC Barcelona']Ver el jugador que tenga mayor Overall(Columna).
df[df['Overall'] == df['Overall'].max()]Ver el jugador que tenga menor Overall(Columna).
df[df['Overall'] == df['Overall'].min()]Ver solo jugadores de Nacionalidad España.
df[df['Nacionality'] == 'Spain']Matplotlib
Funciona para visualizar mejor los datos en un DataFrame.
Importar pandas, matplotlib, seaborn
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as snsFunción que permite visualizar los gráficos dentro de jupyter notebook, debajo del import.
%matplotlib inlineCargar archivo csv.
df = pd.read_csv('data_fifa.csv')
dfVer solo las columnas
print(df.columns)Conocer los rostros reales del videojuego Real Face.
Crear un grafico de barras.
sns.countplot(data = df, x = 'Real Face')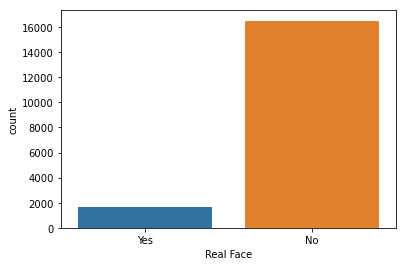
Llamar la paleta de colores, ya que cada que ejecutamos un código, estos cambian. Los colores se componen por índice.
sns.color_palette()
Asignar un color a una variable.
color_base = sns.color_palette()[2]Asignar un color a un gráfico de barras.
sns.countplot(data = df, x = 'Real Face', color = color_base)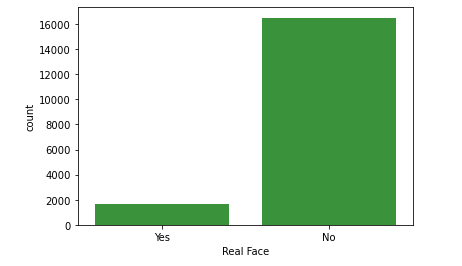
Ver gráfico de jugadores en una posición.
sns.countplot(data = df, x = 'Position')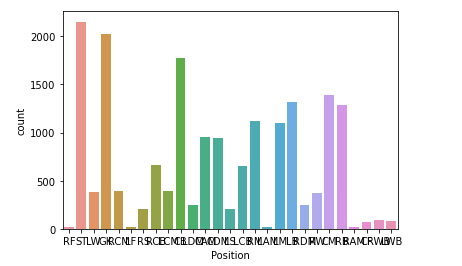
Ver los gráficos, pero con el nombre rotado para que no se vean amontonado los datos.
sns.countplot(data = df, x = 'Position')
plt.xticks(rotation = 90)
Crear variable para que los datos se vean en orden.
order_position = df['Position'].value_counts().index
sns.countplot(data = df, x = 'Position', color = color_base, order = order_position)
plt.xticks(rotation = 90)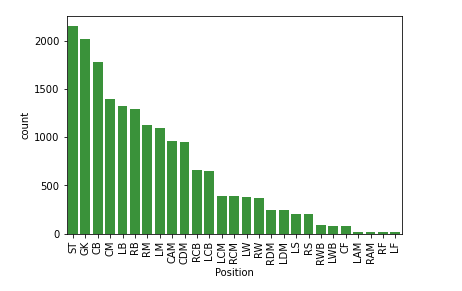
Gráficos Circulares.
Pie Chart o Gráficos Circulares
Importar las librerías.
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inlineMostrar solo las columnas.
df = pd.read_csv('data_fifa.csv')
df.head(4)
print(df.columns)Hacer un gráfico circular de Real Face. Primero limpiar la columna o quitar los valores nulos y ordenado en forma descendente.
sorted_values = df['Real Face'].value_counts()
plt.pie(sorted_values, labels = sorted_values.index)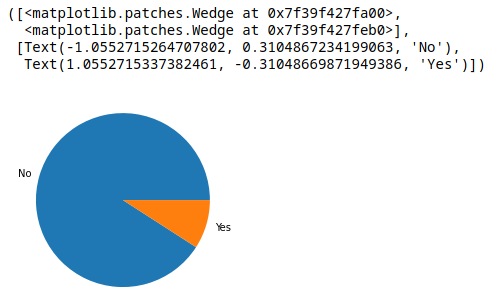
Para que empiece del centro del circulo y no de cualquier angulo.
sorted_values = df['Real Face'].value_counts()
plt.pie(sorted_values, labels = sorted_values.index, startangle = 90)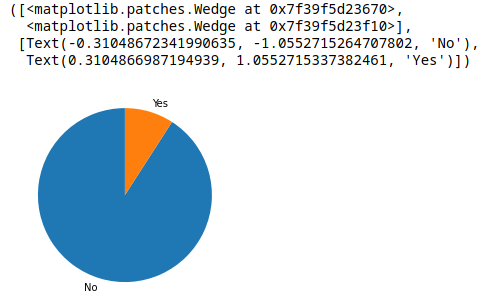
Cambiar el orden, a descendente.
sorted_values = df['Real Face'].value_counts()
plt.pie(sorted_values, labels = sorted_values.index, startangle = 90, counterclock = False)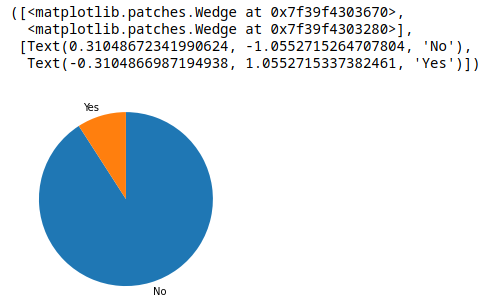
Agregar; para que se vean más limpio los gráficos.
sorted_values = df['Real Face'].value_counts()
plt.pie(sorted_values, labels = sorted_values.index, startangle = 90, counterclock = False);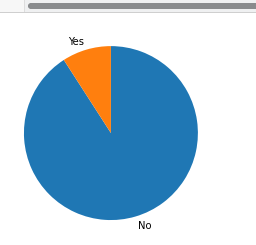
La función axis para poner en óvalo el gráfico.
sorted_values = df['Real Face'].value_counts()
plt.pie(sorted_values, labels = sorted_values.index, startangle = 90, counterclock = False);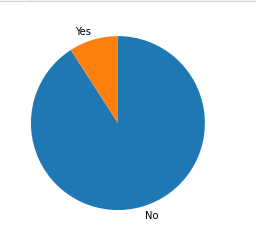
Agregar; para que se vean más limpio los gráficos.
sorted_values = df['Real Face'].value_counts()
plt.pie(sorted_values, labels = sorted_values.index, startangle = 90, counterclock = False);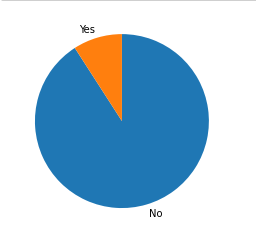
Grafico de dona.
Agregar; para que se vean más limpio los gráficos.
sorted_values = df['Real Face'].value_counts()
plt.pie(sorted_values, labels = sorted_values.index, startangle = 90, counterclock = False,
wedgeprops = {'width' : 0.5});Histogramas
Crear histogramas con Matplotlib, searbon : Histogramas
Primero importar las librerías.
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inlineUsar el mismo archivo adjunto en este tutorial.
df = pd.read_csv("data_fifa.csv")
df.head(4)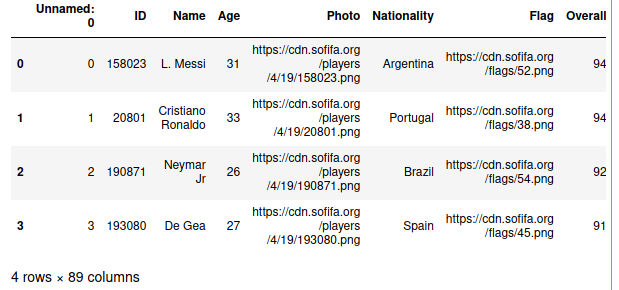
Crear un histograma.
plt.hist(data = df, x = 'Potential');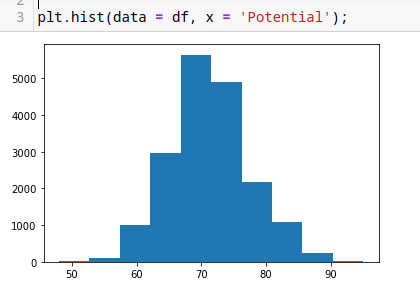
Ajustarlo por valores, podemos usar el código print(df[‘Potential´].describe()) para ver los valores máximos y mínimos del historial, o podemos crear variables con las funciones min y max, también importar NumPy.
import numpy as np
min_valor = df['Potential'].min()
max_valor = df['Potential'].max()
bins_base = np.arange(min_valor, max_valor, 5)
print(bins_base)
plt.hist(data = df, x = 'Potential', bins = bins_base);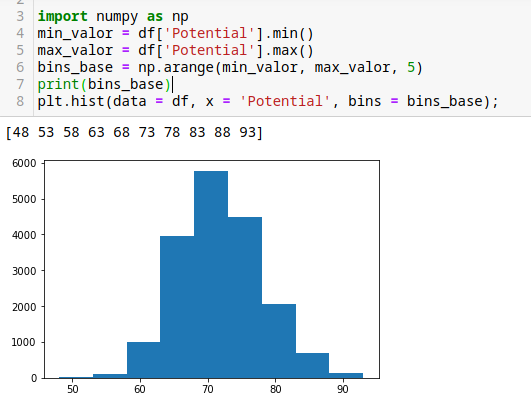
Histograma con seaborn
sns.distplot(df['Potential']);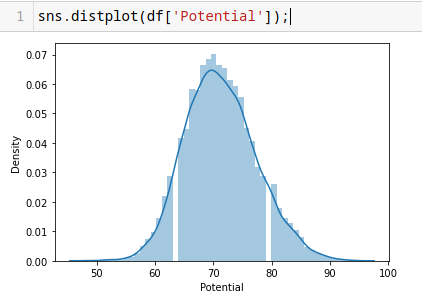
Quitando el contorno.
sns.distplot(df['Potential'], kde = False);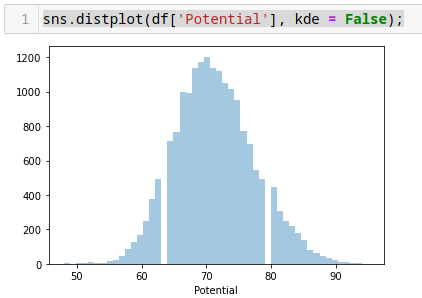
Gráfico de Dispersión.
Histograma con dos argumentos de columnas.
plt.scatter(data = df, x = 'BallControl', y = 'Dribbling')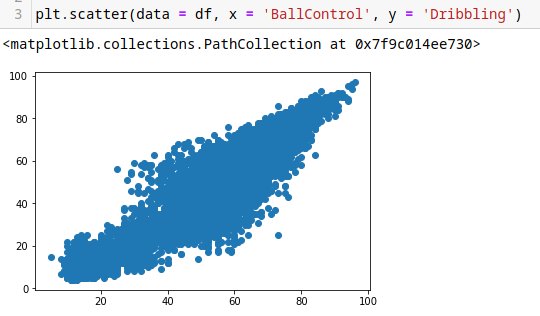
Histograma con matplotlib.pyplot
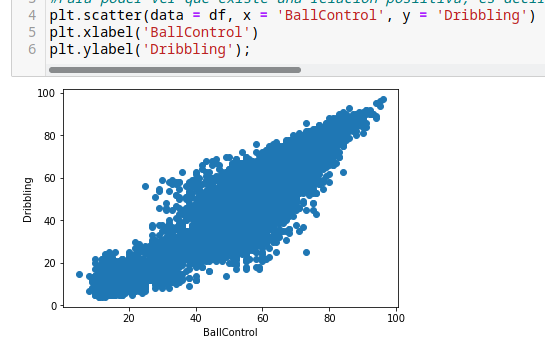
Agregar etiquetas para tener más claro el histograma.
Para poder ver que existe una relación positiva, es decir, cuando mejor se esté desfigurando, más fácil podrán tener control del valor
Es casi lo mismo a diferencia que existe una línea que indica la regresión lineal
sns.regplot(data = df, x = 'BallControl', y = 'Dribbling')
plt.xlabel('BallControl')
plt.ylabel('Dribbling');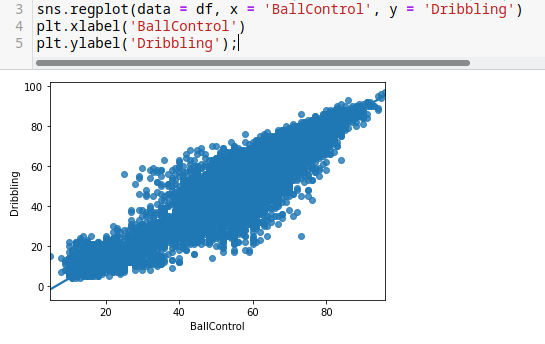
Gráficos de caja, Heat Map o gráfico de calor.
Parecido a los histogramas a diferencia que en Heat Map podemos usar dos columnas para comparar.
import numpy as np
plt.hist2d(data = df, x = 'Potential', y = 'Age');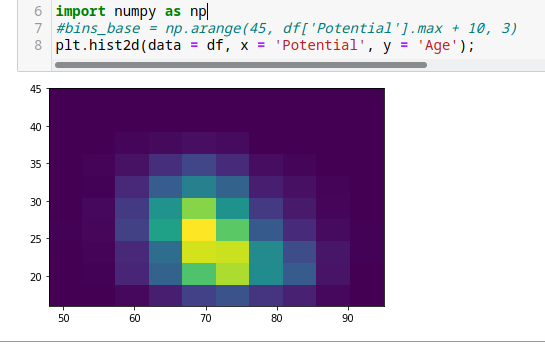
Para conocer que significan los colores
plt.hist2d(data = df, x = 'Potential', y = 'Age');
plt.xlabel('Potential')
plt.ylabel('Age')
plt.colorbar();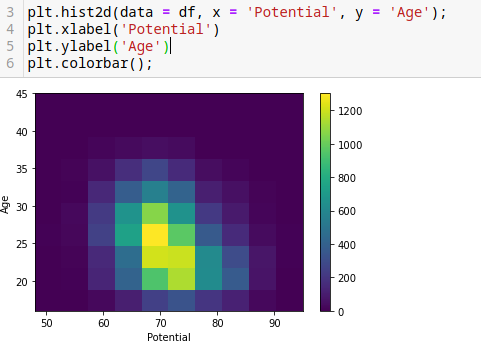
Podemos mejorar el gráfico agregando otras variables y funciones.
import numpy as np
bins_potential = np.arange(48, df['Potential'].max() + 5, 5)
bins_age = np.arange(16, 45 + 5, 5)
plt.hist2d(data = df, x = 'Potential', y = 'Age', bins = [bins_potential, bins_age]);
plt.xlabel('Potential')
plt.ylabel('Age')
plt.colorbar();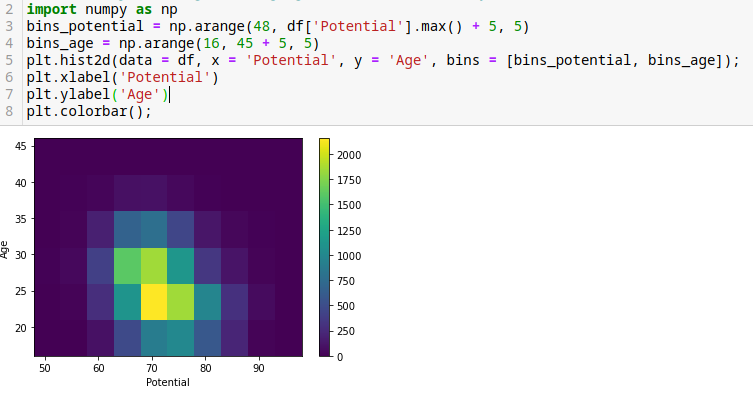
Diagrama de caja o Box Plot, con librería seaborn.
sns.boxplot(data = df, x = 'Age', y = 'Potential');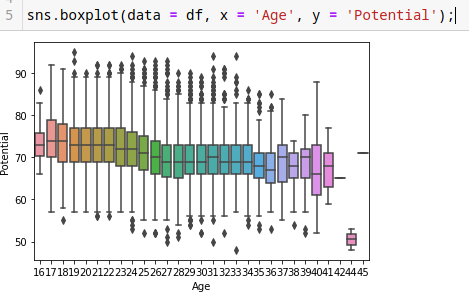
Agrandar el gráfico con la librería matplotlib.pyplot
plt.figure(figsize = [10, 5])
sns.boxplot(data = df, x = 'Age', y = 'Potential');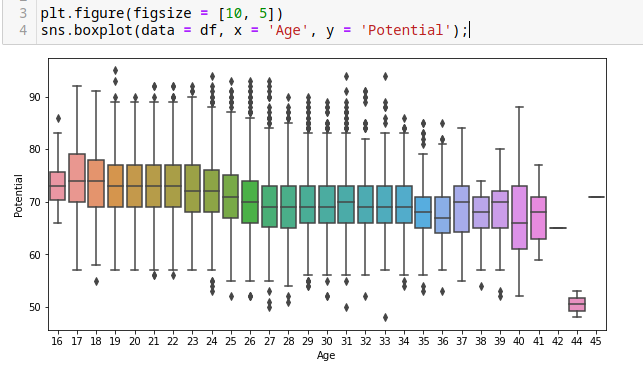
Los puntitos son los jugadores, de lado izquierdo el potencial y abajo la edad.
Para saber ejemplo quien es el jugador con mayor potencial poemos hacer lo siguiente,
df[df['Potential'] == df['Potential'].max()]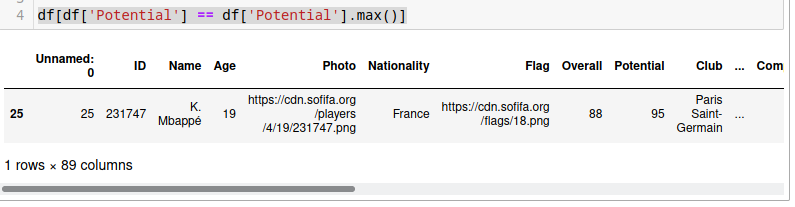
Ejercicio.
Predecir potencial de un jugador.
Ver si las columnas Age y Potential tienen valores nulo
print((df['Age'].isnull().any(), df['Potential'].isnull().any()))Ver la relación entre 2 columnas.
plt.scatter(data = df, x = 'Age', y = 'Potential')
plt.xlabel('Age')
plt.ylabel('Potential');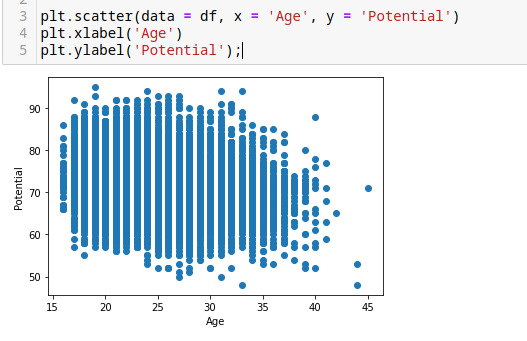
Compararlo con un mapa de color.
plt.hist2d(data = df, x = 'Age', y = 'Potential')
plt.xlabel('Age')
plt.ylabel('Potential')
plt.colorbar();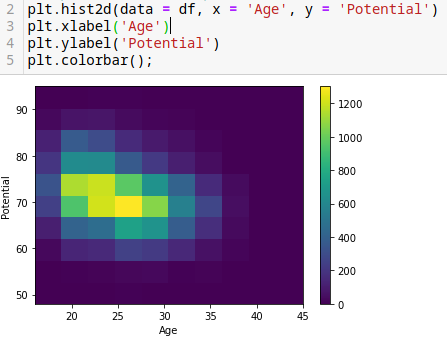
Para extraer datos para testear el modelo, se necesita…
# data traning: x_train = age, y_train = potential
# data testing: x_test = age, y_test = potential
#Libreria sckikit_learn
from sklearn.model_selection import train_test_split
#Dividir
x_train, x_test, y_train, y_test = train_test_split(df['Age'], df['Potential'], test_size = 0.2)
print(x_train, x_test, y_train, y_test)#Entrenamiento
#Primero transformar las dimencones con la funcion de numpy-
#Convert to ndarray
x_train = np.array(x_train)
y_train = np.array(y_train)
x_test = np.array(x_test)
#Reshape
x_train = x_train.reshape(-1, 1)
y_train = y_train.reshape(-1, 1)
x_test = x_test.reshape(-1, 1)
print(x_train.shape)#Seleccionar el modelo
from sklearn.linear_model import LinearRegression
regression = LinearRegression()#Entrenamiento
regression.fit(x_train, y_train)#Prediction
y_predict = regression.predict(x_test)#Comprobr la prediccón
#Observar que un jugador de 19 años, segun la predicción su potencial es de 71.33
print(x_test)
print('\n')
print(y_predict)#Comprobar si la predicción esta bien o mal, buscando el error
from sklearn.metrics import mean_squared_error
mean_squared_error(y_test, y_predict)Entre mas bajo es el error, mejor es nuestro algoritmo de predcción
Gracias por compartir.